Thoughts?
http://blog.onekloud.com/whats-serverless-can-it-save-you-money
A global remote execution environment supporting a variety of languages that encourages message-driven architectures supporting a huge range of use cases. All with a zero cost floor and reasonable average costs for low/mid workloads.
And this is a problem because?
You answer with a rhetoric question. Ok, that’s a thought. 
This reminds me of:
####Serverless Microservices - Ben Vandgrift & Adam Hunter (Clojure/Nov 2015)
Their “thrift” approach was to “decompose” their functionality in such a way that they could take advantage of the cheapest service provider for each infrastructure service - so in a way the architecture was heavily influenced by the diversity of their infrastructure vendors.
I think this simply drives home how design thinking is more and more forced to move away from “re-usability” (in order to reap the maximum reward from the initial development investment - which typically ends in “legacy software”) towards “replaceability” and “composability”.
Startups tend to do rewrites as they mature anyway (example Wunderlist (1,2,3, To-do)) but as they do they need to take infrastructure costs into account as it may be time to move to a cheaper (but possibly less convenient/higher maintenance) platform/option. I guess by the time you are furnishing and maintaining your own infrastructure you should have a much clearer idea of what your software actually needs to be.
Product vendors often had “batteries included” offerings and the convenience that afforded lured (locked) people in. Infrastructure service vendors now do the same thing. But while “batteries included” products are often costly to change, it can become costly to stay with a “batteries included” infrastructure service as your service becomes more busy/successful.
So ironically, while technically serverless can scale well, the cost of serverless may not scale all that well and any CIO needs to stay on top of that and plan accordingly. For a truly successful venture “serverless” may just be a “quick fix” starting option.
Maybe it’s time to take “batteries included” from the the “Pros column” and put it into “Cons column” because it usually translates to “lock-in” in one way or the other. Focused, replaceable, and composable seems to be where things are going.
I run my own servers, and I’ve always found that running my own servers will run circles around cloud providers and at a tiny fraction of a fraction of the cost (which I’m happy to do as I know how to manage servers).
Not really sure how else to answer. The OPs original quote was from some pretty angry CEO railing against dark fiber, and custom designed data centers. I laughed a little at how absurd the quote was. It’s like saying that GenServers are the devil and then throwing in some nonsense about global warming and Russian hacking.
No, I don’t think Lambda is the devil, or “one of the worst forms of proprietary lock-in…in the history of humanity”. It’s a stateless execution environment. It works well for a lot of use cases. Not so well in others.
You might be able to argue that the disparity between what major internet icons can accomplish, vs “the little guy” is so great that the little guy will never be able to compete against the likes of X, Y, or Z because they can’t afford billion dollar global data center networks or arrangements with Tier-1 network and storage providers.
Only that entire argument is bogus because anyone can leverage such an ecosystem at pretty reasonable rates. Sure, I suppose once your competition starts leveraging this system, you need to you as well in order to keep feature/cost parity. But in that case, it’s really economics itself that ends up being the worst form of lock-in.
I’d be interested to know what scale you’re talking about here. There are certainly things that Lambda isn’t good at. And at a certain request volume, it’s better to saturate a reserved EC2 cluster. That said, once you start to manage multiple data centers, even with a small number (say 10 servers each) the overhead starts to add up quickly. At least in my experience. Running your own cage sounds like fun. But in my experience, the TCO is far greater than the equivalent setup on AWS. In fact, in AWS we end up with a better setup because of the flexibility and scalability it provides. This is all before you start to add in things like a data warehouse or large-scale disk storage or global CDN.
PS: Why has Industry Talk turned into Rage Against That Guy Over There Talk?
I have a few servers in a few areas mostly around the USA (one in canada). For file hosting (statically generated site that was very often updates along with actual decently sized file downloads) I had to support a few million unique connections per day. NGinx handles this all fine and a few minutes of sync time between servers was fine for my use. That was my heavy load, hundreds of terabytes a month, averaged well over 4000 connections per second with spikes up to 60k connections per second. It did run a Discourse forum as well in a docker instance with another for postgresql (I actually ran a few discourse instance for various groups).
In addition some of the servers did heavy compiling (a combination CI, build system, production builder, and it also built the static sites mentioned above) that would pretty well swamp the 24 core Xeon server it ran on, almost always under constant load.
In addition to a few dozen smaller sites that I host for various groups.
All for less than $500/month, only 3 primary servers and a few VM’s.
I did look into Amazon once and for my usage it would have cost me over $20k/month.
So yes, I quite consider that most people who run on Amazon either have no load at all, or just love wasting money.
I would easily and happily hire a dedicated server tech group of people if I had to grow more than that, the money I’d save hiring them would easily be far far greater than what I’d have to pay to Amazon.
Google Cloud was not any better either (I think it was worse actually).
And all in all I had a couple of hours downtime once over a 10 year period because of some Internet routing issues at the time that I had no control over (it affected a good bit of the Internet at the time).
So your entire operation is 3 hosts, including a 24 core Xenon (last I checked those were ~$7k for the CPU alone) including networking (with 200TB/mo outgoing data xfer), power, cooling, storage, etc? All for $500/mo? That’s a pretty good price. Respect. In fact, it seems too good to be true. 200TB/mo in network xfer should cost you more than $500 alone. Given that it should take most of 3x 1G connections to push that data, and in my neck of the woods those are $500/mo/ea.
It’s also still just 3 servers solving what sounds like a pretty well-known problem. You don’t sound like you’re running an IT shop where a developer is going to walk up to you and ask for a 5-node Riak cluster, a Mongo cluster, OpenFire servers to handle 6M concurrent users, etc. The QA director needs a QA environment for testing and validation, your partners want another environment, and so on and so forth. It doesn’t sound like you deal with data center costs or hassles.
You can get decent per-host pricing on EC2 with reserved instances. You can set up a static site with file serving on S3 + CloudFront without servers easily. In your scenario though, AWS data xfer costs blow your budget out of the water. Or at least I can’t do it on a $500/mo budget. It sounds like you run a pretty tightly optimized shop, efficiently (although without a lot of headroom for failover). Again, respect.
I think though, a lot of startups start with very little traffic (and very little know how). A good number of them would be completely fine running within Amazon’s free tier. A good number of those would do even better if they didn’t have to figure out how to properly manage EC2. That’s where serverless comes in. The small or even medium business that wants a small website. Maybe their web guy who knows JavaScript is able to spin up a quick REST API for his awesome Electron app (snark). Serverless reduces the startup costs to nearly zero, with very low pay for what you need add-ons after that.
Serverless isn’t for everyone, but I think the world is better off with it as an option. Once you decide you need 300, 3_000, 300_000 hosts, it becomes a matter of running your own data centers or running within Amazon’s data center. There the lock-in lies in the amount of data you have in that provider.
Well the center I use allocates 1gbit dedicated up/down per each of the 2 servers there and I can use it as much as I can push across it, and their system itself reported those values.
Nope, all my built things, even Docker on it is very new.
I may indeed be quite unique in that I needed utterly massive amounts of bandwidth and CPU time both, but I absolutely needed both. ^.^;
I got rid of most of that work about 1.5 years ago though, dealt with it for almost 5 years was fun at first, but I really hated dealing with the people that I had to deal with… Nowadays I keep the relatively minor couple dozen sites that I host for others along with a few dozen of my own things going, I average 100gigs transfer in a month now (occasional spike to a few terabytes when things get released, but otherwise eh, it’s a fraction of what I did a couple years ago).
If you blogged about your setup, how you evolved it, how you maintain and deploy to it, and as an added bonus, how Elixir fits in, I’d definitely read it. Sounds like a success story to me.
I like that AWS is fairly simple to setup and it does have a wide range of services that are more or less easily pluggable and provide a lot of tools that make it easier for a non-devOps to deploy “something”. I’ve looked at a few dedicated instances outside of aws and comparatively they’re quite cheaper and my next step will be to try one in full, since for 20/30$ month you get a machine that can pretty much run a bunch of websites that don’t have much traffic (so for me as a newcomer it will be more of a learning exercise). But I like that AWS takes care of a lot of security stuff for me, because I learn by doing and going through tutorials and articles - sometimes I feel like I really don’t understand what’s happening underneath but it works, so I imagine that having someone block the most common attack vectors is a good thing. It’s also cool that you get replication, availability, ability to size up/down easily, but at the same time, it all comes with a cost and while I agree that for most projects in their initial phase it’s actually cheap/free, it does seem to increase in costs quickly, as in they scale as you scale. On the other hand finding someone who’s capable at devops and cheap is also problematic for sure, so it might as well be more expensive.
For anything of significant scale AWS is just horrible pain and if you are small they will just ignore you when there are issues. Small being less than few mil per month
It turns out the quote is from the CEO of a company that does enterprise Kubernetes. I respect Kubernetes. It does a better job of orchestration than EC2 Container Services. Yet the company’s mission is to:
help you along your journey through container adoption
Including, navigating through:
My goodness. There are tons of companies that will see benefits from something like Lambda before ever needing to navigate the 4 easy steps of Kubernetes adoption.
outside of exotic scenarios the only use cases where lambda would be an OK choice would be served much better by shared hosting 
I’ve thought about it but honestly I really don’t want to remember dealing with such people ever again, I love managing that stuff, so if some people drove me from it you know they had to be bad…
I did run ‘One’ Elixir server on it, most of the server far far pre-dates Elixir though. ^.^;
I had a lot of Erlang servers on it, a couple Python servers (quick flask whip-ups that needed nothing special), a few PHP things (in a VM, because screw putting PHP on the main server, this was before docker too), eventually ran a few Discourse instances in docker later on, had a few C++ servers, a couple Java servers (in a VM again, because again screw that crap, Jenkins has so many bugs!), and a few other things that I don’t recall off hand, with nginx fronting it all when I switched to it, hmm, 5-7 years ago, apache2 before that, and apache1 before that.
Nowadays I still run a few erlang servers, 2 python flask servers, php in it’s VM’s still ticking away (occasionally need to rollback files because PHP stupidity, yay snapshots and logs), and a ruby thing somewhere (not my creation unlike most of the prior, even some but not all of the PHP stuff, just something that I’m hosting for someone).
In my opinion serverless architecture only make sense for cloud (public / private ) when you are building system from blocks.
One of this block can be serverless for short running tasks. But you can’t build all stack only using only serverless. There is no sense for long running as will be more expensive. Example of long running task can be some data mining, big data processing …
The Cloud Guru is build on AWS lamda
According to Cloud Guru
So what defines serverless architecture?
There’s no exact definition, but I think there are some basic characteristics that define a system as serverless:
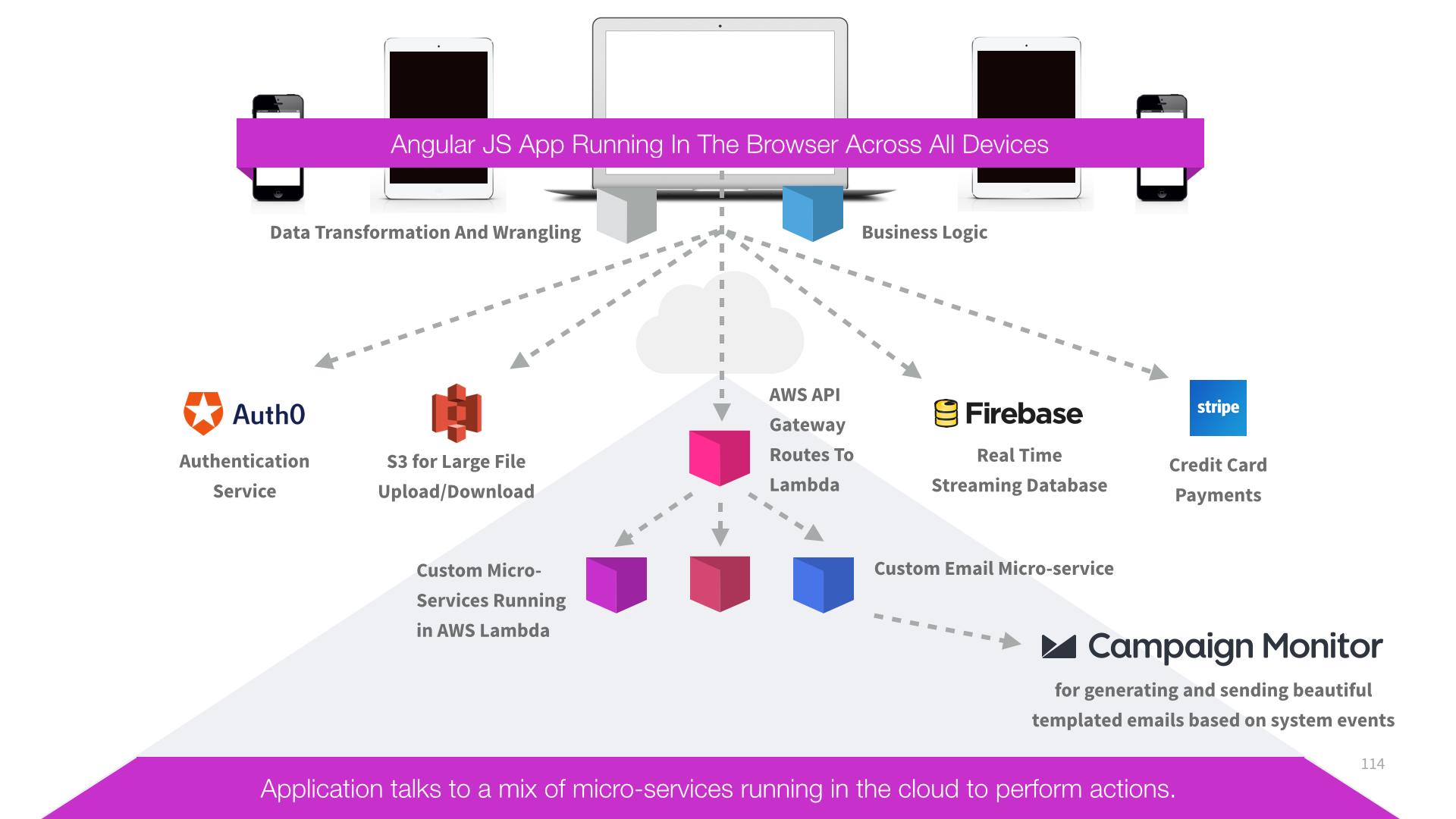
Operators do not need to run and maintain back-end servers themselves
The vast majority (~ 95% +) of the code-base resides in the front-end
The code that does reside in the cloud, is only the code that absolutely must (ie. for security purposes some work must be done with access to secrets that the user’s browser cannot be trusted with)
The front end acts as the orchestrator calling a rich array of cloud-based services to perform specific functions (such as taking a credit card payment, giving access to protected resources, shooting off emails or push notifications in response to events)
https://www.youtube.com/channel/UCqlcVgk8SkUmve4Kw4xSlgw
Danilo Poccia is the author of AWS Lambda In Action, a book about building event-driven serverless applications. In today’s episode, Danilo and I discuss the connection between serverless architecture and event driven architecture.
just a thought … do you run docker on your own servers … or is that just silly trendy overkill
/me bets 5 BGN that @OvermindDL1 runs IllumOS.
I actually use docker pretty heavily, it makes it easy to take snapshots and move containers around as I need.
Sadly no, my things predate Illumos by quite a bit and even Solaris well before they added linux support. ^.^;
We’ve been looking at it for some things at work though.
Well there is SmartOS so you could be running both ![]()




















© Copyright Elixir Forum | Terms | Privacy & Cookies