I watched this video the other day and thought it was pretty interesting.
In the video the presenter discusses how at Amazon they have moved a number of services from relational databases to a single table DynamoDB design. He talks about using the single table and global secondary indexes to support all the access patterns that a relational database would provide but that is significantly cheaper than running your own database even if hosted on AWS. In addition, it is auto scaled and there are seemingly no scaling issues you’d ever run into.
I’m curious if anyone here has tried this approach and has thoughts to share on the good/bad? He also said that you can do this with any NoSQL database. Really thought provoking. I’d previously been all in on relational (and specifically Postgres) after having had issues with Mongo (we’d modeled everything in a normalized way which is the exact wrong way to go about it - first database I had used as a beginner and was always annoyed there weren’t joins ). The single table DynamoDB route seems rather appealing though.
Isn’t the big big thing that you lose out on the database typing information so it is very very easy to get very bad data into the database, in addition to slower joins, duplicate data, etc… etc…?
The lack of typing is what allows you to use a single table as opposed to a table per entity. I don’t know how they prevent bad data from getting in but the fact that much of Amazon runs on DynamoDB now (including the shopping cart service among others) it must not be much of an issue? Also, with only a single table you’d never need to do joins. As long as you’ve carefully planned your access patterns you can efficiently query the data. In his talk he said that you can basically replace any relational database with a single DynamoDB table. The only exception to that is when you have certain types of time series data (not sure what the limitation is?) and in that case you would have two tables. I’d imagine that duplication of data isn’t much of an issue with a single table design. Typically in NoSQL you would denormalize and duplicate data if there were multiple tables/collection/etc. because joins aren’t supported.
In the talk he says that OLTP applications (i.e. CRUD apps) can all be modeled as a single table. The main issues with relational databases is that they optimize for the wrong things. It used to be that storage was the most expensive part of the data center so relational databases were normalized and optimized for that environment. Now the most expensive part of the data center is CPU and that is what NoSQL is optimized for.
Anecdotally it seems there is a lot of hate for NoSQL in general. However, it seems like that may be based on people trying to use NoSQL incorrectly. I don’t know much about it but that talk made me think NoSQL and specifically DynamoDB might be something I ought to look at in the future (Guess their talk/sales pitch worked on me )
Or using a typed language as a higher up, but then you still have to deal with migrations across it all, but most likely they are just good at hiding errors (I know I’ve suddenly had a cleared cart over the years for seemingly no reason). ^.^
If you have a row with data that references another row and you want both rows but only know the first row then how would you do that in a single query without some form of join? o.O
Sounds like offloading lookup work from the database (where data access and transformations belongs) to the application (which is usage of the data belongs). Those concerns should not be mixed like that… O.o…
It’s not hard to replace any entire database with a single KV store sure, but that doesn’t mean it will be efficient (no optimizes joins and transformations and so forth, and most don’t have efficient transactions either if they have transaction support at all), safe (oh let’s just store a 4 character string here that starts with ‘bob’ when the sql table has constrains that force only 5 character long strings or more that don’t contain bob in them, the KV store would store that just fine with no check), and what if you have conflicting primary keys between two very different areas of your program, so now you have to worry about prefixing everything correctly, which may not be easy to do if building up from smaller parts that each were built with total ownership in mind (how would you handle that migration ^.^;), etc… etc…
Thus meaning you need joins to be able to reference data on multiple rows in the same query based on data in another row.
Well I also have very negative thoughts about CRUD as it is (horrible horrible misdesign) so… ^.^;
A SQL database is not a simple CRUD store and using it as such means it is not being used properly. It is significantly more powerful around a whole set of features of data storage, transformation, transactions, and more.
I’m not sure SQL is optimized for space, at all… Every SQL server I’ve worked with uses heavy checkpointing, journelling, etc… This trades off extra space usage for significant efficiency gains. You can even pick the type of storage you want for a given table (want efficient sharded KV style storage in postgresql on a table, trivial, want a B-Tree, sure, want to use an external Oracle database like it’s a local table, absolutely). I’m not sure when storage was ever the most expensive part at any datacenter I’ve worked at, and I’ve worked at some big ones the past 10 years (many-multi-terabytes as well as tens of thousands of sharded variants). The remote network traffic throughput and report generation were always the costly bits (the network traffic throughput for sql can be significantly smaller than on pure-KV databases as you can pick and choose and transform the data precisely how you want it returned to you, and report generation is always a horror it seems due to their seemingly designed-for-inefficiency, but that’s not database related).
Wish I could watch, this is why I hate videos without a full text version of their information… ^.^;
I haven’t really seen a lot of hate for NoSQL’s, rather I’ve seen a lot of hate because people use data storage incorrectly. SQL isn’t the be-all-end-all by far, but pure NoSQL’s are ‘usually’ the wrong thing to use because that’s not how the data actually ‘is’ as well as most of them have no abilities to transform the data or minimize network and processing overhead. Sure NoSQL’s will look up something fast and cheap but that’s in exchange for having to do the formatting and processing work in your application instead, implemented by someone who almost certainly is not going to be ecking out performance in the transformation via fine-turned AVR usage and so forth that a modern database would be doing, so it’s not cheaper, it’s often a lot more expensive instead (for amazon this means moving the CPU costs from the database to the users server application instead, where they charge for CPU usage). In addition, every time I’ve seen a NoSQL used it would be better served by either using a time-series database (extreme throughput needed) or by using something like PostgreSQL, not just because PostgreSQL is SQL, you can use KV stores in it just fine, but because when you do use a KV store in PostgreSQL you still get the advantages of data transformation and network minimization and all, which saves time, cpu costs, and minimizes the amount of front-end code that you have to write, upkeep, and debug unlike having to do all that transformation work yourself in the application layer as is required to be done by NoSQL’s (often significantly more inefficiently as well). You can even use Graph Structures in PostgreSQL, or other databases, or other Query languages, or whatever else (same with a lot of that with Oracle as well, which is another database I’ve often used the past 10 years).
Based on what he was saying it didn’t appear to me as if he was talking about offloading a lot of work to the application. He emphasized the importance of identifying access patterns beforehand so you can minimize data transformation. Basically, the data is already formatted exactly how you need it to be formatted. Sure, you’d need to format it the right way to store it how you want. They can support multiple access patterns with reverse lookups and overloading the GSI’s. If you need calculated or derived values he recommended using Lambda to calculate values and store them again in the table metadata for easy lookup.
Definitely not the right solution for every problem. He said relational obviously works just fine for line of business applications and smaller stuff. His main point was that a lot of apps start seeing massive traffic and relational databases have trouble keeping up whereas a properly designed NoSQL store is generally a good fit for the job. Reminded me of a post I read awhile back about these two competing Pokemon Go apps. The first was designed with the normal app and database deployed to a Digital Ocean or other server setup and basically fell apart because it couldn’t scale to meet the needs of the influx of users even though they kept adding hardware. The second app leveraged a NoSQL store and some other serverless services and it scaled to millions of users for like $100/m. I think the second guy was tooting his own horn a bit but it was amazing how much he was able to do for so little money (assuming he’s telling the truth).
I personally have been looking to learn some of these serverless options as it seems like a good route to go if I ever did have an app idea that went gangbusters. I’m mostly just curious if anyone here has used DynamoDB or another NoSQL store as described by the guy in the video and what their thoughts were looking back. According to AWS, it’s worked extraordinarily well for them.
If you want predone transformations then in a SQL system you can just use a (materialized) view, which is basically a single-table-looking interface to potentially vast amounts of pre-transformed data behind it.
And lambda on AWS is even more expensive. ^.^;
That’s almost always just because of lacking proper index setup or using the wrong key types or so forth, half-decent design prevents those issues and actually makes one think about how the data should be stored to begin with. I’ve never yet seen a SQL database that was not pretty easily optimizeable by either fixing some really really bad queries or adding an index or two. And the bit about ‘properly designed NoSQL store’ works just as well as ‘properly designed SQL store’, except the SQL store would be faster for anything but non-trivial key lookups (of which things like postgresql have table types optimized for schema-less KV access as well, without losing any of the other features).
That sounds significantly like a difference of design, not a difference of database. 5 years ago I was hosting a server that averaged 20-150 TB of month, 10-150 million unique IP’s with billions of accesses a month on a single dedicated server (which was significantly overpowered for the actual use since it also doubled as a Java build server, still only ~$300/mn; under heavy web load it still didn’t even fill a couple of its cores in CPU power and I never saw the web related services exceed a total of~20gigs of RAM) that ran for over 5 years, and yes it used PostgreSQL. Proper design makes a significantly better difference than what database is chosen, but a well designed and featureful database can make a proper design far more simple.
Related to that server 5 years ago I did look at migrated to AWS at the time, instead of costing my ~$300/mn (but that included being used as a significant java build server as well), just using the web stats (not acting as a build system) and transfer rates I calculated an absolute minimum of costing me over $30000 on AWS using their own values (what really bugs me is how pleased the website seemed with those values…). Considering this made me no money as it was pure open source work, that was well WELL outside of what I could handle. I can see AWS being useful if you have really bursty but rare traffic or you have a pretty significant income source and don’t want to deal with running your own server or you really want maximum uptime (although my server uptimes are higher than AWS the past 10 years, lol), but it’s really not that hard to hire a good server DBA and IT admin for companies and even that would save them so much money to run a good dedicated system (keeping in mind how to scale if the need ever arises). But if a company has really bursty and rare traffic and don’t have their own IT staff then sure, AWS seems fine enough.
Wanted to say thanks for this thread! Lots of interesting information all around.
I’m wondering if sacrificing the schema in the database is less expensive in languages that have a static type system. Amazon uses Java I believe, perhaps that helps
I have seen many teams trying to not use an RDBMS. Only one succeeded and that was because their use case wasn’t a perfect fit for an RDBMS anyway (a huge log of arriving events).
NoSQL is not a panacea but it’s curious to me how periodically people again start believing that “it will work this time”.
Do not get tempted by new cloud tech. The IT world keeps forgetting that this new cloud tech has made trade-offs and sacrifices in order to have a compelling use case at all.
(As for the price inside AWS, well that’s an artificial advantage; if they want to push Dynamo then of course they’ll make it cheaper initially. But will that be true 2 years down the road?)
DynamoDB is not much different at its core by many previous incarnations of the idea, incl. MongoDB – a promise of speed of ingestion, quick direct read access (by ID) and… almost zero good querying or grouping capabilities, poor concurrent performance, and often – no transactions.
Far too many programmers forget that it if the app you’re doing with the new tech (in this case DynamoDB) becomes financially successful then other people come along – accountants, financiers, investors, managers – and they will require reports and generally stuff that mandates all sorts of complex queries.
As @OvermindDL1 said, it might seem like NoSQL is cheaper or quicker but that’s only initially; you are basically taking a loan and you will be repaying it – with a heavy interest – later in your application’s code.
And finally, I’d cynically remark that “thinking really hard about requirements and shape of data” is applicable to any technology, not just those of Amazon.
After the above video I had to come to the conclusion that getting NoSQL right can be far more difficult. It seems people interpret “schema-free” as “no data modelling required” and it turns out to be quite the opposite. And people assume that their structured object data could serve as the item (document) schemas.
With RDBMS you simply model the data ERD without needing to know anything about the access patterns. The access patterns typically come into play later through query optimization, index optimization and in more drastic cases, denormalization (which typically requires triggers) when more is known about the production operational profile.
Also NoSQL proponents always point out that denormalization is OK because storage is cheap - but normalization also means that there is only one place that has to be updated rather than multiple denormalized places (besides the eventual consistency and strong consistency debate).
And then it comes to embed vs reference issue which can significantly affect performance. It seems to come down to:
Embed what you DO need.
Reference what you DON’T immediately need.
Embed partially denormalized data that you DO need when the full item isn’t immediately needed.
In object-based systems often the full object graph is instantiated to extract partial information - according to what I’ve come across with respect to Key-Value/Wide-column/Document NoSQL stores that is not a good idea. The motto seems to be “denormalize partial data for embedding”. So NoSQL as an object store doesn’t seem to be all that generally effective.
Then even within the same category of store there can be some divergence in the data modelling strategies (e.g. DynamoDB vs Cassandra both classified as wide-column stores).
RDBMS can also lead to some bad habits - it’s all too easy to end up with a monolithic store:
It’s too easy to create yet another table in an existing schema.
Further incentives to keep lots of tables in the same schema:
It’s easy to simply join tables.
A single connection gives access to everything.
There is no need duplicate or synchronize data.
So in some circumstances it may make sense to segregate a monolithic schema into context/service schemas even if it means that some data is duplicated:
Having small separate schemas makes it possible to optimize each store separately - possibly by replacing it with an optimized NoSQL solution.
I think the crux of the matter is that there is no good cloud/on-demand/per usage RDBMS equivalent, so serverless solutions are forced to use NoSQL from the get-go even though working with these stores requires quite a bit of highly specialized knowledge and skill.
Not true; all joins would be self-joins, but you’d still need joins unless you massively duplicate data, with all the consistency problems that brings along…
What do you think of the theory that Amazon’s new DocumentDB service is implemented on PostgreSQL? (Based on the very close matchup of capabilities and restrictions.) Would love to find out if that’s true
i.e. for NoSQL to shine it has to be treated as a conflation of a data store and a precomputed cache (which is what Advanced Design Patterns for DynamoDB seems to be about). That conflation may be an acceptable tradeoff when the optimization is genuinely needed but it makes the item schemas extremely brittle because they need to change whenever the access patterns change (even when the source data in the store doesn’t change).
I keep coming across this naive point of view that revolves around optimizing access for a single path through the data. Unless your application is truly trivial, you will require many different paths through the data. Traditional relational dbs are pretty good at optimizing different access patterns through a normalized data structure, on the fly as the access is requested. NoSQL dbs are good only at accessing a pre-computed path via a key. Multiple paths? Figure them out in advance, and duplicate the data in advance.
Most NoSQL (ignoring graph DBs here…) are really just modern iterations of hierarchical DBs, and there are excellent reasons why relational DBs mostly displaced hierarchical DBs decades ago–the ideas discussed here are mostly not new. (The new aspect is JSON as a lingua franca for data storage and exchange, and also a way to have a per-record embedded schema.) This kind of unnormalized storage has its specific use cases, the tradeoffs are well-understood, yet about every decade or so a new wave of folks latch onto hierarchical storage as a magical solution to problems they don’t understand.
(Meanwhile, I get to observe at a distance the joy that some folks are having with a system where contractors insisted on use of a NoSQL database, then proceeded to normalize the data going into it and try to query it like a SQL database. It is not working well; debugging is difficult, scalability is terrible, and costs are exorbitant.)
there are seemingly no scaling issues you’d ever run into
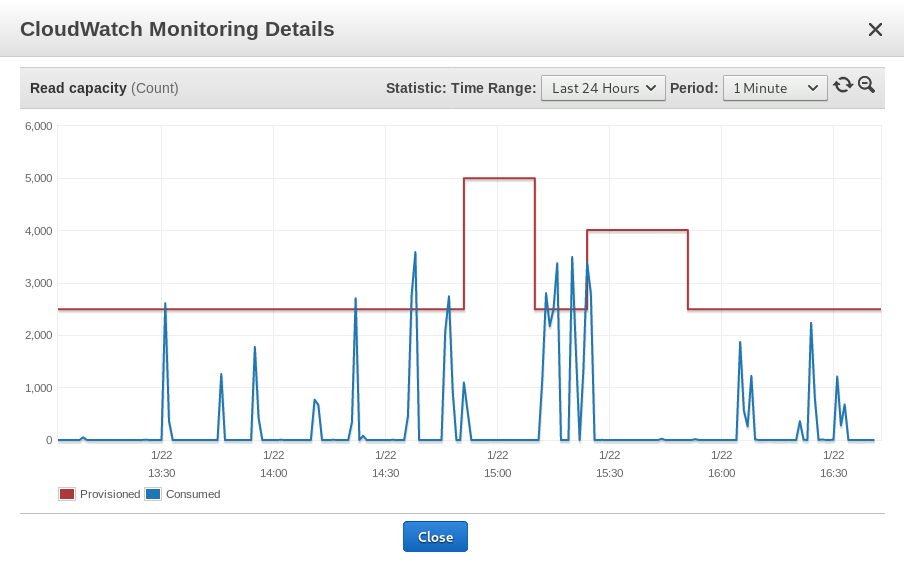
I have to comment in current production applications I run, I have found this basically useless if you have a spiky work load - and I imagine many applications would. Here is a chart of read throughput vs available throughput - the spike hits a “read throughput exception”, many many minutes later it scales up after the spike has gone, then scales down and the pattern repeats. So basically we have to provision for the max spike - rendering autoscaling useless.
I’m sure this has been touched on in the discussion, but in my experience it also offloads a lot of complexity to the application to deal with schema changes over time, data not conforming to the expected structure, data integrity etc. As with all things, it’s all about trade-offs and for some use-cases it is the right choice, but may not be as simple as it seems.
He emphasized the importance of identifying access patterns beforehand so you can minimize data transformation.
This is basically what you do with Cassandra, you need to know the query first before building the schema. You build the schema around your query.
Unless your god you’re not going to know all queries. I think most people use Cassandra as a fancy 2D hash data structure.
It sounds like you’re really hype about this tech.
I personally think hash tables are terrible at modeling relational data and it’s inflexible.
I usually advocate for figuring out what your data is and what you want to do with it then pick your database technology. I also believe the majority of the data out there can just run on relational and then from there as needs evolve choose a nosql that works in tandem with it.
Shopping cart data is pretty dang easy so a hash table is no brainer. Another use case would be affiliated coupons. But I think the case is small and the return in investment in learning Cassandra or DynamoDB may not be worth it. This is coming from a guy who did Cassandra and Elasticsearch.
@ryanswapp i watched the same video and that idea with a single table also brew me away. up till then i’ve been using dynamodb as a relational db, having a bunch of tables etc, so i thought i’d give the single table a try, after weeks of trial and error i think i’ve got my app running with a single table reasonably well.
The biggest pain I’ve found is that you really do need to know the access pattern before-hand, like really really do, else you’ll be in a world of struggle.
I spent way too much time thinking about the various access patterns, or the possible patterns i might need in the future, instead of focusing on the app…in a way your app is now limited by the patterns your db is able to support, which makes me a little un-easy. sure there are GSI and LSI to help, but still that’s a paradigm shift.
The other thing is, after you do have the patterns, if you molded your data accordingly, then decide to change afterward, especially if you need to change the range key value to support different sorting, it could be a huge pain because now all the relevant data has to be updated.
Thanks for the response. Glad to hear from someone who has done this in the wild. It sounded to me like this is a good option for a service that is well defined and not likely to change and that needs to scale. Like you mentioned, you would need to really know the access patterns before doing so. Amazon used the example of the Amazon shopping cart service. It probably hasn’t changed much in years. Good target for this approach.
Most of all, I thought it was refreshing to hear a different take on how to store your data. If this option works for a particular service it is probably a pretty stellar option.
This may be mitigated these days, but one of the scarier things I heard about DynamoDB is that if you have hotspots in your data - such as one customerID that has 40x the traffic of the average customer - you have to provision for the 40x IOPS or else you will get 50X errors for exceeding your query quota. That may mean you’ve got a lot of partitions idle, with one very hot one. And you have to pay 40x for the idlers because you can’t allocate different IOPS for different partitions of the same table.
Have you run into that, or considered it in the design of your table?
 ). The single table DynamoDB route seems rather appealing though.
). The single table DynamoDB route seems rather appealing though. )
)