I’m hacking around, trying to support Elixir as a target for m2cgen.
To be able to merge the support for Elixir on m2cgen, the test suite needs to pass and execute in a reasonable amount of time.
So far, with the help of @josevalim I was able to optimize the tree-based models well enough that they’re no longer a problem for running the test suite.
However, SVM-Like models are too slow to compile.
Here there are 4 examples of the same model, exported with varying max line-lengths for the sub-expressions.
Varying the max length of the lines made no difference in compilation times, but the super_small version makes it easier to read and understand what the code is doing.
In the end, I need help figuring out if there’s a way to generate better code for these expressions, in order to make compilation times faster.
The first thing that comes to mind in the SVM code is:
-
you are converting everything to a binary first thing. don’t do that for anything from m2cgen. if the goal is to work with large amounts of data, lists are not a good representation, at all. Instead expect the input to be a binary.
-
you are reading the same input multiple times. This was not a problem in the other examples but seems to be one for SVM. So I would do this as the first thing on top:
<<v1::float, v2::float, v3::float, ...>> = input
And then use v1, v2, instead of calling read. Not sure how much it helps, but it should help a bit.
if the goal is to work with large amounts of data
The goal is to receive lists which usually have between 10 or 20 items. On the test suite, the biggest input has ~200 items or so.
Would these magnitudes count as “large amounts of data”?
And then use v1, v2, instead of calling read. Not sure how much it helps, but it should help a bit.
Ok, awesome
Once again, thanks for the tips 
I created a “benchmark” for the compiler, where I have a function return one expression. I control the length of said expression (the 1+1+1 part)
defmodule Test do
def run() do
1 + 1 + 1 .....
end
end
I benchmarked and charted it, where X is the amount of "1"s and Y is seconds to compile.
The compiler presents quadratic behaviour, given the expression size:
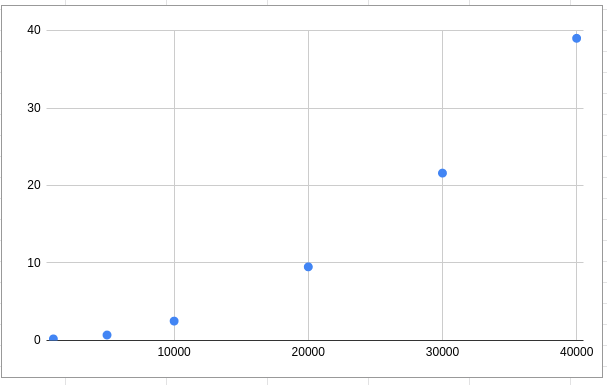
Then, I decided to try to wrap the each line in https://github.com/lucasavila00/ex_m2cgen_examples/blob/main/nusvm_model/super_small_lines.ex with an anonymous function.
When wrapped, the quadratic behaviour is gone, and the file compiles in ~3s now.
For the record, I can now run the entire test suite (186 models) in 10 minutes, which is totally fine for m2cgen CI, I guess. All tests passing 





















