
lucasaas98
Upgrading Oban/Pro/Web causes database load spike
Hello again!
Following yesterday’s topic success we have tried to deploy the new version with the updated code to production but we are running into issues where the database load spikes to 100%. I have a feeling this would not happen if we had shorter pruning time for our jobs table since the same issues does not happen in other environments like our Sandbox environment but would be great to really understand the underlying issue.
For reference, this is the update:
Oban: from 2.17.3 to 2.17.10Oban Pro: from 1.3.0 to 1.4.9Oban Web: from 2.10.2 to 2.10.4
And our database:
- PostgreSQL 13.13
- 2 vcpus
- 7.5GB ram
I have some screenshots and evidence from our Cloud SQL instance that should help to understand the issue, I will include them in details tags so the thread looks nice.


Query 1 and call times

SELECT
$1
FROM
"public"."oban_jobs" AS o0
WHERE
(o0."meta" ? $19)
AND (o0."meta" ->> $20 = $2)
AND (o0."meta" ->> $21 IS NULL)
AND (o0."state" = $3)
UNION ALL (
SELECT
$4
FROM
"public"."oban_jobs" AS o0
WHERE
(o0."meta" ? $22)
AND (o0."meta" ->> $23 = $5)
AND (o0."meta" ->> $24 IS NULL)
AND (o0."state" = $6)
LIMIT
$25)
UNION ALL (
SELECT
$7
FROM
"public"."oban_jobs" AS o0
WHERE
(o0."meta" ? $26)
AND (o0."meta" ->> $27 = $8)
AND (o0."meta" ->> $28 IS NULL)
AND (o0."state" = $9)
LIMIT
$29)
UNION ALL (
SELECT
$10
FROM
"public"."oban_jobs" AS o0
WHERE
(o0."meta" ? $30)
AND (o0."meta" ->> $31 = $11)
AND (o0."meta" ->> $32 IS NULL)
AND (o0."state" = $12)
LIMIT
$33)
UNION ALL (
SELECT
$13
FROM
"public"."oban_jobs" AS o0
WHERE
(o0."meta" ? $34)
AND (o0."meta" ->> $35 = $14)
AND (o0."meta" ->> $36 IS NULL)
AND (o0."state" = $15)
LIMIT
$37)
UNION ALL (
SELECT
$16
FROM
"public"."oban_jobs" AS o0
WHERE
(o0."meta" ? $38)
AND (o0."meta" ->> $39 = $17)
AND (o0."meta" ->> $40 IS NULL)
AND (o0."state" = $18)
LIMIT
$41)
LIMIT
$42
Query 2 and call times

SELECT
$1
FROM
"public"."oban_jobs" AS o0
WHERE
(o0."meta" ? $4)
AND (o0."meta" ->> $5 = $2)
AND (o0."meta" ->> $6 = $3)
AND (o0."state" IN ($7,
$8,
$9,
$10,
$11,
$12,
$13))
Query 3 and call times

SELECT
$1
FROM
"public"."oban_jobs" AS o0
WHERE
(o0."meta" ? $13)
AND (o0."meta" ->> $14 = $2)
AND (o0."meta" ->> $15 IS NULL)
AND (o0."state" = $3)
UNION ALL (
SELECT
$4
FROM
"public"."oban_jobs" AS o0
WHERE
(o0."meta" ? $16)
AND (o0."meta" ->> $17 = $5)
AND (o0."meta" ->> $18 IS NULL)
AND (o0."state" = $6)
LIMIT
$19)
UNION ALL (
SELECT
$7
FROM
"public"."oban_jobs" AS o0
WHERE
(o0."meta" ? $20)
AND (o0."meta" ->> $21 = $8)
AND (o0."meta" ->> $22 IS NULL)
AND (o0."state" = $9)
LIMIT
$23)
UNION ALL (
SELECT
$10
FROM
"public"."oban_jobs" AS o0
WHERE
(o0."meta" ? $24)
AND (o0."meta" ->> $25 = $11)
AND (o0."meta" ->> $26 IS NULL)
AND (o0."state" = $12)
LIMIT
$27)
LIMIT
$28
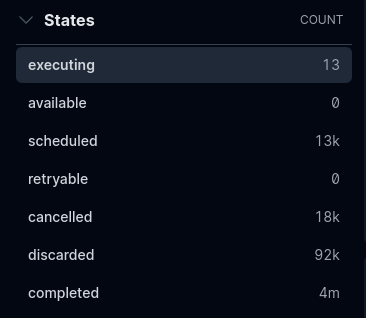
Any ideas? Did I miss something in the changelogs that could have caused this?
Thanks for the help and sorry for the fat finger ghost thread I created just before ![]()
Most Liked

benwilson512
Can you \d oban_jobs? I’m curious to see exactly what indexes are / aren’t in place.
As a workaround for efficiently clearing out completed jobs like this I have sometimes used this approach:
begin;
lock oban_jobs in access exclusive mode;
create TEMPORARY table useful_oban_jobs as (select * from oban_jobs where state != 'completed');
truncate oban_jobs;
insert into oban_jobs (select * from useful_oban_jobs);
commit;
This ends up being much faster than a delete + vacuum believe it or not.
Overall I’d consider using partitioned tables if you want millions of jobs around, although Postgres 13 being nearly 4 years old at this point I don’t recall how good its support for partitioned tables is.

sorenone
Heya,
Those ^ are queries from Workflows.
Here is a link to the specific migration that should help!
We’re currently working on better centralized migrations.
benwilson512
And to add on to this if you’ve been dealing with a large number of jobs deleted I’d consider a vacuum full oban_jobs but do note that this will lock the table while it rebuilds. We’ve had issues with table bloat on the oban_jobs table when we get heavy delete activity.
Popular in Questions






Other popular topics







 Latest Oban Threads
Latest Oban Threads
Latest on Elixir Forum
Sponsor Spotlight

Move fast and fix things! Error tracking with less noise for Elixir devs who love to ship. Start your free dev account.
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #elixirconf-us
- #advent-of-code
- #distillery
- #processes
- #forms
- #api
- #metaprogramming
- #security
- #hex
Our Sponsors

Build Elixir applications with speed and confidence.

Supporting innovation across the BEAM ecosystem.

We build reliable cloud platforms for business-critical systems.

Catch errors, track performance, monitor hosts and more.
Error tracking for Elixir devs who love to ship. Start your free account.

Practical resources that improve the lives of professional developers.

Enabling companies to succeed by building software people love.

The deployment platform built for Elixir: PaaS ease, VPS control.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.

Courses that'll move you from confusion to "Aha, now I get it!"