I’m creating a GenServer process that monitors the creation/configuration of a cloud server.
These GenServer processes will only live as long as the creation/configuration takes, and I’ll need to monitor them from another process for two exit cases:
Creation/configuration successful (normal exit) – go to next step in server management process
Setup failure (non-normal exit/crash) – examine last state, take corrective action based on failure type
I’m having a bit of trouble deciding the best architecture for this workflow. Supervisors seem most geared to restarting processes on crash, but I may or may not want to restart a crashed process depending on what happened. And they don’t seem to be geared to handle ‘next step’ logic on a normal exit. Furthermore, when I’ve used Supervisors in the past, I’ve put as little business logic in them as possible, as this seems like a misuse of their intention.
I looked at handling everything in the GenServer’s terminate callback, passing messages to another process to take the next step, but this documentation from GenServer seems to counsel against that: “Therefore it is not guaranteed that terminate/2 is called when a GenServer exits. For such reasons, we usually recommend important clean-up rules to happen in separated processes either by use of monitoring or by links themselves.”
So at this point, the best approach I can see is not using a Supervisor to create/manage these GenServer processes, but instead write my own parent process that does either:
And, I suspect I might be missing something, as there’s a nagging feeling I’m mis-using OTP or unaware of some more standard approach to achieve my outcome.
:transient - the child process is restarted only if it terminates abnormally, i.e., with an exit reason other than :normal, :shutdown or {:shutdown, term}.
I don’t think so, because that doesn’t give me any access to the state of the terminated GenServer for next steps, nor allow me to make a decision on a crashed process if restarting is the correct next step.
Based on your description launching “expendable” processes is a legitimate survival strategy. There is some sense that the parent process is some sort of (configuration/configuration) “protocol sequencer” responsible for completing one of many possible paths through the protocol - so outsourcing all the “dangerous work” to separate processes makes sense.
Sounds like a good use case for using separate Tasks in sequence to do the dirty work.
It’s not either or. Use a Supervisor, have the children be :temporary but start them from a separate process that monitors the children after they’re created. The Manager (or whatever you want to call it) will be the one starting the children (through the Supervisor), but they’ll be started and linked properly to a Supervisor, so the Manager doesn’t concern itself with crashes and the processes are still linked and managed in an easily swappable module.
defmodule YourApp.Server.Supervisor do
...
def start_child(params) do
Supervisor.start_link(__MODULE__, ...) # etc.
end
...
end
defmodule YourApp.Server.Manager do
...
def start_server(params) do
{:ok, pid} = YourApp.Server.Supervisor.start_child(params)
process_ref = Process.monitor(pid)
...
end
...
end
This does seem cleaner. One thing I’m unclear about with this approach: is there a danger of a race condition between the Supervisor creating the process and the Manager monitoring it? In my testing, when I’ve run Process.monitor(pid) on an already dead pid, I get no indication that the pid is dead, and of course the monitoring process would get no alert about the pid dying b/c it’s already dead.
Put all the things that can invalidate a server start in the init of the server process so that you won’t even return {:ok, pid} on start_child. Obviously you’ll have to handle failure to start with a case or some such in that case.
Theoretically it’s always possible that the millisecond you spend before monitoring is when a process dies and as with a lot of the asynchronous signals in erlang, I don’t know what happens when you do this exactly when a process terminates, but in that case you could defer any server-killing logic until the manager sends a message to the server, i.e. something like GenServer.cast(pid, :go). You could then call that when you’re absolutely sure that all the init logic is done and you’ve got a monitor set up.
Edit:
As an addition to this, I wanna clarify that I think you should view passing init as almost a guarantee that things will go allright. It’s useful to know up-front whether or not something makes sense and passing init means you have a pid. Not passing it means you don’t, so it’s a pivotal point in the lifetime of a process.
It’s not wrong to pass init without guaranteeing success, because there are things that can’t be known, but it’s always useful when you can without locking up other processes that are waiting for the start to finish.
Edit 2:
Don’t take any of this as gospel. It’s very probable that there are differing opinions on some of these things. I personally just find these ideas useful. It’s also extremely underrated to just have fun with processes and sometimes trying out things that might not even be all that great.
You’re right! That’s what I get for assuming w/o writing test code So with that being true, I can guarantee I won’t lose track of any processes the Manager would start through the Supervisor.
Thanks to all who commented, I think I now have a clear picture of how to cleanly architect this.
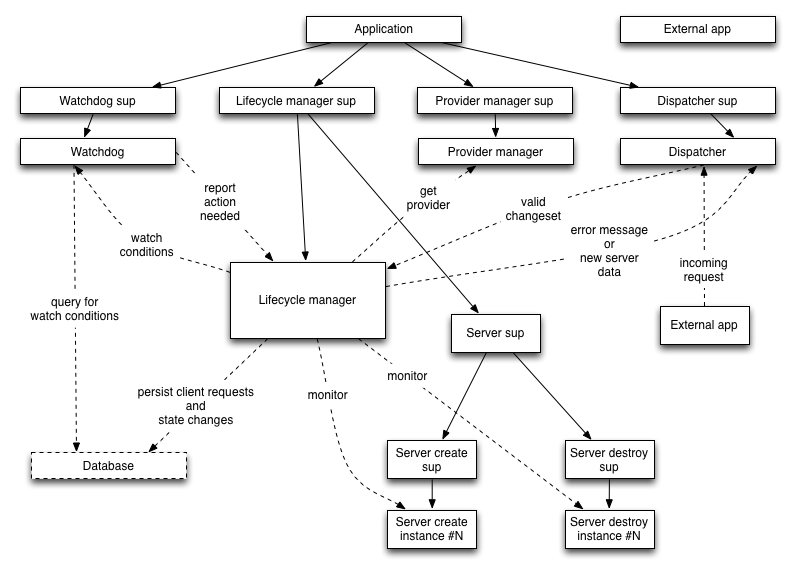
@gon782@peerreynders attached is a spiffy OmniGraffle diagram of the process tree I’ve settled on, if you’re curious. Solid lines are linked processes, dashed lines are monitors/messages.
I’m pretty happy with this overall architecture, we’ll see if it morphs as I dig into implementation.
A spiffy diagram indeed! Report back with how this went and what issues you ended up stumbling upon, I’m sure it will be a nice learning experience for readers of the forum.
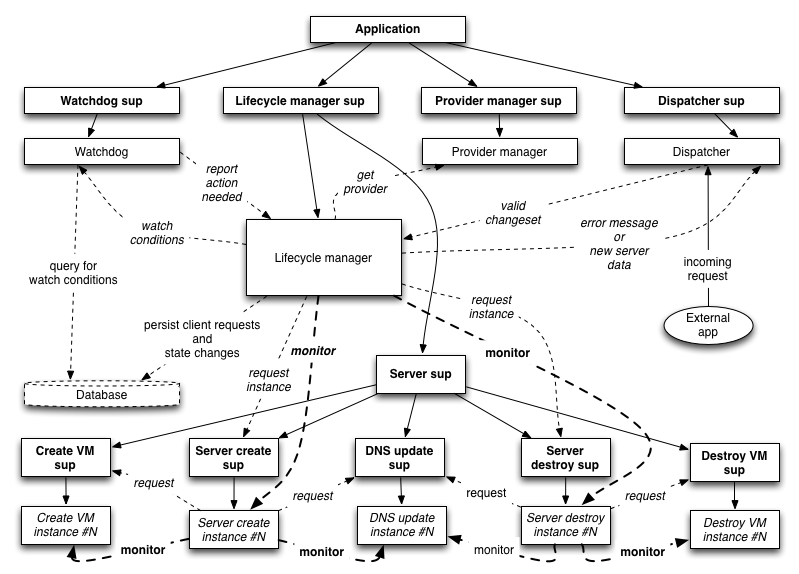
Yet spiffier diagram which illustrates the create/destroy process workflow in more detail.
The interesting thing to me with this implementation is the parallel task nature. For instance, creating a VM in my case involves both the API commands to the VM provider to spin up/configure the instance, and a separate set of API commands to my DNS provider to create an associated A record. Especially given the DNS propogation time, it makes sense to run these tasks in parallel such that the complete server is up and running in the minimal time possible.
Forcing myself to think in terms of OTP/process architecture makes the design step a lot more challenging (thus the visual aid), but the resulting design seems proportionally cleaner and more robust.
Really enjoying digging back into the Erlang/OTP mindset that I first cultivated many years ago
This looks quite interesting! I think you’ll enjoy this Erlang/OTP article on setting up an “Error kernel” for your system, that is the part of the code that you must be able to rely on and is isolated from crashes in the system. Looking at your diagram the error kernel would probably be the Lifecycle manager.
Your diagram looks like a reasonable start (but I don’t count myself qualified to give you good advice).
Call me old fashioned, but I don’t think any running Erlang process can handle data durability like a relational database. Data integrity is their deal, and I think I’d have to be managing an obscene amount of VMs in order for it to become a bottleneck.
At the moment, my approach is to have the lifecycle manager record all state changes on all managed VMs in the database. With that as my source of truth, a crashing lifecycle manager would mean re-initing state from the database on recovery. I could have an error kernel type process that keeps that state in Erlang as well, but that feels like introducing extra complexity where it’s not needed.
Still, it’s a great programming concept, especially when combined with the onion layer thing, and certainly worth thinking about…