This article provides a good breakdown of how Phoenix works. They state in there
The PubSub leverages erlang PG2 - Named Process Groups to create a named group of process. The process groups are maintained across nodes and all the distribution is handled by erlang.
For example if you create a process group namedfoobarthen we can get the list of all the process assigned to it from any node and send messages to them.In phoenix there is a PG2 GenServer
Phoenix.PubSub.PG2Serverthat is spawned up for each new topic; on a node. It is responsible for receiving messages from other nodes to broadcast to all the channel GenServer (that have subscribed to that topic) in local node .Then there is local PubSub GenServer
Phoenix.PubSub.Localwhich uses ETS to store the pids of the local channel GenServer that subscribe to that topic and when a broadcast request is sent to this local PubSub it retrieves all the local pids of that topic and sends the message to the channel GenServer.Why have this local PubSub, why not just register all the channel GenServer to the PG2 group and let them handle the broadcast message directly. The reason I think is that it allows for less node to node message passing hence not throttling the network. So for each broadcast there can be up to N number of messages sent across nodes where N is the number of nodes in the cluster.
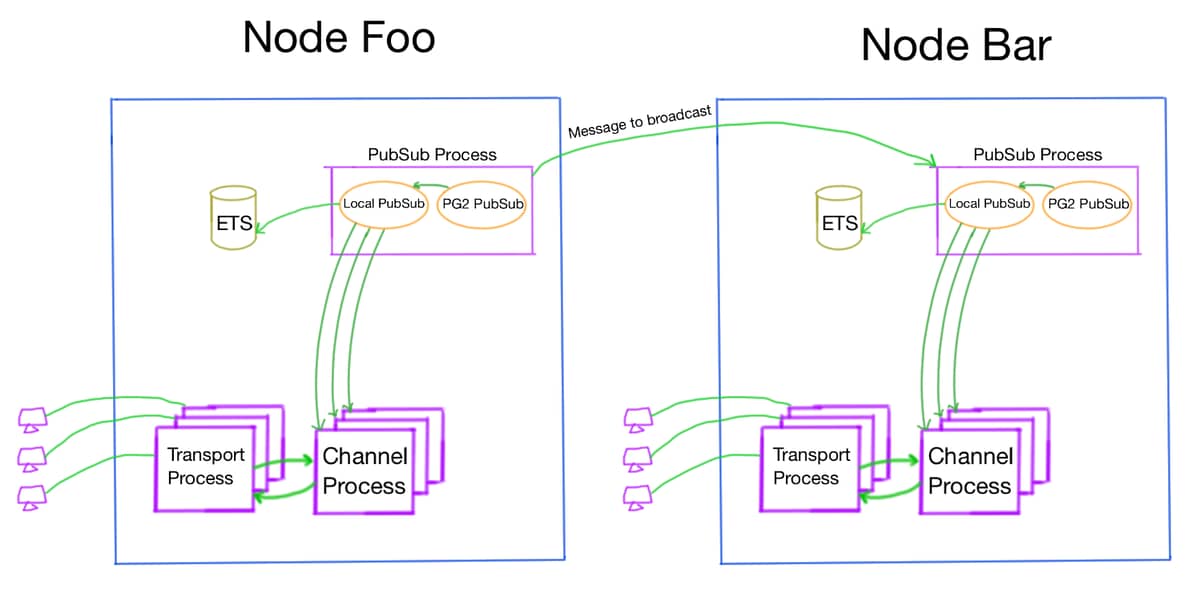
It is not exactly intuitive to me how this all works. However, it seems this is basically PG2 group communication between the nodes and then just genservers via ETS cache of users on each node being sent messages to update them and share the data with the users.
I also note that the Syn project states:
Syn is a Process Registry and Process Group manager that has the following features:
Global Process Registry (i.e. a process is uniquely identified with a Key across all the nodes of a cluster).
Global Process Group manager (i.e. a group is uniquely identified with a Name across all the nodes of a cluster).
Any term can be used as Key and Name.
PubSub mechanism: messages can be published to all members of a Process Group (globally on all the cluster or locally on a single node).
Subclusters by using Scopes allows great scalability.
Dynamically sized clusters (addition / removal of nodes is handled automatically).
Net Splits automatic resolution.
Fast writes.
Configurable callbacks.
Processes are automatically monitored and removed from the Process Registry and Process Groups if they die.
They also state:
Syn is a replacement for Erlang/OTP global’s registry and pg modules.
The writer of the package @ostinelli posted here to clarify that nodes can easily join or leave Syn. And there is a great article I just found on his site explaining the superiority of his system in many regards.
Question
If one is trying to replicate the group creation/messaging and registration functions of Phoenix (without Phoenix), we have PG2 as well, but why not just use Syn instead? It seems Syn would be a perfect candidate.
It seems this is exactly what it was designed for. I am not sure how important the ETS tables and other optimizations in Phoenix are to it. But presumably they could also be applied in a Syn system if there are obvious bottlenecks to overcome. (Or maybe they already are?)
I would likely imagine there would be no major bottlenecks worth obsessing about in any practical system and the convenience of a single system like Syn would outweigh the benefits of chasing those. The author’s benchmarks tests seem to show Syn works fine as is.
It seems to me Phoenix is good for very narrow purposes when it does exactly what you want. But if you are building a custom system Syn will be much better for handling that part.
Any thoughts? Pros and cons?





















