As I said in this post:
Is not about the authentication/authorization code, but how it’s used by the developer to protect access to the resources in his application.
As I said in this post:
Is not about the authentication/authorization code, but how it’s used by the developer to protect access to the resources in his application.
@Exadra37 how do you respond to this?
If the authentication is penetrated then I am not sure there’s much that can be done. Sure you can’t access everything but you can access quite a lot. And you can very likely collect links to resources owned by others – even if you can’t access them right now. You could escalate your authentication attack and get access to other users and still enumerate resources by using private dashboards – like /my-posts et.al.
What good do random IDs do here? I can write a crawler in 1 hour that does recursive scraping. And I am not even that good of a programmer anyway.
Same. I feel like there is some exaggeration here. Maybe a big number of organizations get penetrated. But are they a large percent of all organizations? @Exadra37 any data?
Never happening, so all sorts of consultants will have lucrative post-production jobs until the apocalypse.
It was always quite funny for me though: a project saves something like $50,000 a year from salaries, the project is almost dead and unworkable 3 years later – so they saved $150,000.
But then they hire some handsomely paid consultants to save the project and they take $30,000 a month and all the savings are gone in less than 6 months – and that’s only if they hire one. If only they hired well-paid and professional programmers before it got to that point, right? And it likely would have ended long ago, successfully.
Short-term thinking is what is making jobs for the consultants. But hey, that’s fine.
My opinion, and strong emphasis in opinion, is that it’s not about being more secure but mitigating potential vulnerabilities.
Suppose you have a set of private resources, and you should only be able to see them if and only if you are the owner of that resource. The way to access that resource is through an URI that contains the raw id of the resource.
Let’s imagine that you didn’t just forget to implement an authorization system, but that you had a bug in it and if affects access to those resources, accidentally granting access to them to other users, or maybe some users that happen to have the same role but aren’t the resource owners. And your test suite didn’t catch it, so it went to production.
If you were using autoincremented IDs in the urls, and somehow a malicious user notices this bug, all they have to do is to enumerate your contents and gain access to all resources they should not be able to. That can be quite severe.
If you were using something that is hard to guess, you can limit the impact of the attacker on your system to only those resources of which the attacker knows the URI. You’re just putting a burden, but it can buy you some time before more damage is done.
So to my eyes it’s not about making your system more secure, that’s very debatable, but about mitigating damage. You still have a bug and a big red flag should be raised so you fix it ASAP.
I wouldn’t assert that you must not use guessable ids in URIs, simply because I don’t have enough experience to give such advice. But if I can limit the damage someone can do by exploiting some subtle bug with such a cheap solution, then I no longer have a reason to use the raw ids anymore. It’s more or less the same reason you return a 404 instead of a 403 for your internal endpoints, so they can’t trust there’s actually something there.
Of course I may be dead wrong.
I already said countless times that is not about bypassing authentication/authorization, but the lack of it due to developer error or whatever.
I will try to illustrate once more.
You are seeing an x-ray sent by your doctor via an application, you click on it and you notice that in the browser opens https://examplle.com/xray/123456789.pdf, and then if you try https://examplle.com/xray/123456790.pdf you got an xray from another patient.
So did you break authetication/authorization here? Clearly not.
Did the developer failed to implement correctly authorization controls? Clearly yes.
Can you now enumerated all xrays in the system? Clearly yes.
Now take an url like https://example.com/xray/kaejlajfpjksl.pdf:
Can you now enumerated all xrays in the system? Clearly not.
Can you now write a crawler?
Unless you find another endpoint point like https://example.com/user/123/all-xrays then you cannot write a crawler.
No, you are deadly right ![]()
and one of the few persons getting the point about not using numerical ids to prevent severe damage in case authentication/authorization mechanisms are not being used correctly and/or buggy.
One of the sites that you can keep track of some public data-breaches:
But that accounts just for what the security researcher is able to gets is hands on.
The majority is in the dark-web. For example LinkedIn was only aware of it’s data-breach several years after it occurred, and that’s only one example of a big player where things just came to light 4 years later:
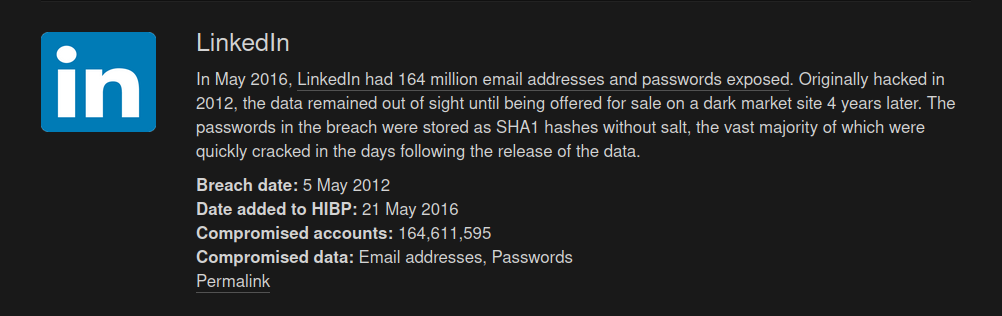
What about this data breach 9 years old?
Now departing: your airline customer data.
Malaysia Airlines faces the daunting task of investigating over nine years’ worth of compromised data after learning of a “data security incident” at a third-party IT service provider that exposed Enrich frequent flyer program member data from March 2010 through June 2019.
Do you get the point why things are so bad at the eyes of keeps regular tabs on whats going on?
This were just two examples, many more exist, that are not on the websites I linked above, but may be in other websites, while others are yet to come out from the dark corners of the web.
To not mention the companies that hide their data-breaches or downplay them, like the recent case with Ubiquiti:
A security professional at Ubiquiti who helped the company respond to the two-month breach beginning in December 2020 contacted KrebsOnSecurity after raising his concerns with both Ubiquiti’s whistleblower hotline and with European data protection authorities. The source — we’ll call him Adam — spoke on condition of anonymity for fear of retribution by Ubiquiti.
“It was catastrophically worse than reported, and legal silenced and overruled efforts to decisively protect customers,” Adam wrote in a letter to the European Data Protection Supervisor. “The breach was massive, customer data was at risk, access to customers’ devices deployed in corporations and homes around the world was at risk.”
Ubiquiti has not responded to repeated requests for comment.
According to Adam, the hackers obtained full read/write access to Ubiquiti databases at Amazon Web Services (AWS), which was the alleged “third party” involved in the breach. Ubiquiti’s breach disclosure, he wrote, was “downplayed and purposefully written to imply that a 3rd party cloud vendor was at risk and that Ubiquiti was merely a casualty of that, instead of the target of the attack.”
Emphasis is mine.
If you want to keep tabs in API security issues weekly then subscribe to this:
Do you want to keep tabs daily for data breaches and/or security incidents?
I don’t know why is that factor even a discussion. If the dev screws up it’s game over.
Are we not talking about websites with actual UI? They have links.
Now if we are discussing headless REST APIs then yeah, then I’ll agree with you.
Of course they can’t enumerate but they can still find quite a lot of info – if we are talking about websites (UI) that have links.
OK, I think I’ll bail out because we’re going in circles – even if we seem to agree on most points.
But last thing I think is a good argument is that you’re linking to companies that CLEARLY didn’t want to invest in good devs.
So what do these links prove except that big companies are cheap as hell?
Why do you think they’d listen to your advice, or mine, or anybody else’s?
You still don’t get it, and at this point I gave up of trying to explain it ![]()
Just figurative or not, call it an url you grabbed while doing a MitM attack to a mobile app, whatever, the principle is the same for enumeration, just the difficulty of getting them changes, because in a mobile app it requires a MitM attack.
IMO we agree on a lot of stuff but we got hung up on meaningless details.
I am stepping out, this thread shouldn’t be a chat that is mostly between me and you.
And chances are that the info is limited to the affected user, but not your entire userbase.
I mean you still have a severe bug that needs to be fixed, but you can hope the damage is not too big. It’s just a complement.
If breaking old urls to implement this change is not an issue, it’s a fairly simple to implement measure to help you cover your back just in case. It has practical use with little downsides, and is more useful than discussing if argon2 is better than bcrypt or pbkdf2(when at that point your entire database and probably infrastructure was compromised already).
There’s a lot of violent agreement in this thread, and most of the discussion seems to focus on the fact that you would still have a bug and it’s not a security measure, which is true, and that you should have a proper security system in place, which is the ideal but we all make mistakes.
Things can go wrong so it’s better to have something to mitigate your errors, even if they’re small things, than to have nothing.
I feel the last point was somewhat poorly communicated through this whole thread, so I wanted to give some perspective on it with some real life examples, since initially the discussion went in the lines of “I don’t get why enumerating is an issue”. Then it’s up to each one to decide if it’s an issue for their use cases or not.
My takeaway is that having the raw ids in your url is not a security issue, but if a set of conditions are met and you happen to have a vulnerability somewhere, they can make it easier to spot and exploit by a third party. You can decide that at that point everything is lost, or you could take a best effort approach against the unknown. It’s like “let it crash”, it’s not about writing buggy software because it “just restarts”, but to mitigate damage in case of ephemeral errors.
I think it’s a sensible thing to do by default, like blocking all ports except the ones that are intended to be used with a firewall, to use www to avoid accidentally sharing cookies with other subdomains, and that sort of stuff. Small things that are inexpensive and can save you if you ever mess up.
I don’t work in the software industry so I lack a lot of experience with bigger projects and teams to properly understand what makes you think that this id thing maybe isn’t worth it(if I’m reading this thread correctly). What I do is mostly for fun but I still am dealing with real people that put their trust into me, so I try to do my best at it. In this regard the advice given in this thread has a lot of value.
Today, I have received the issue #127 of the apisecurity.io newsletter, and the last article(bottom of the page) talks about numeric IDs enumeration from the point of view of a security researcher:
I strongly recommend anyone to read the pen-testing guide overview(its not a deep technical article) to have a better understanding about what it is at stake, and learn some new stuff.
The newsletter TLDR for the the article:
Pentesting: Finding IDORs>
Broken Object-Level Authorization (BOLA, also known as Insecure Direct Object Reference or IDOR) is one of the most dangerous and frequently found API vulnerabilities. It happens when API calls include an identifier of a resource and the API grants access to that resource without checking caller permissions.
Max Corbridge published a great article on the methodology for finding BOLA/IDOR vulnerabilities:
- Determine whether the resource being referenced is public (not a big deal) or private (should not be >accessible).
- Find patterns in API route naming to discover new endpoints.
- Try adding IDs even to requests that don’t have them.
- Try replacing parameter names.
- Supply multiple values for the same parameter.
- Try different operations (HTTP verbs) on the same path.
- Try changing the request’s content type.
- Try using numeric instead of non-numeric IDs.
- Sites allowing to save credit cards or adding users (e.g., to chats) often have IDOR.
- Try changing the requested file types.
- APIs often implement a CRUD (create/read/update/delete) approach to resources, so try them all.
- Try using arrays instead of regular values.
- Try wildcards instead of values (e.g. *).
- See if error messages leak data.
And so on. Max provides useful explanations and examples for each of the tips – so definitely worth checking out.
A lot of other people were participating ![]()
Here it is a fresh example why numeric ids in the URL are bad:
https://twitter.com/apisecurityio/status/1382317721623351301?s=09
Information of 1.3 mln Clubhouse users also scraped via APIs and posted by attackers. IDs in Clubhouse are sequential which made it easier to enumerate the records. Records expose anonymous social account owners.
The tweet retweeted in the above tweet:
https://twitter.com/henkvaness/status/1381612643694305280?s=20
I can see who invited who, the twitter account, the Instagram account, the photo URL, the username, follower count, time created. This is a scraping job, not a hack.
The entire data set:





















© Copyright Elixir Forum | Terms | Privacy & Cookies