
RobertDober
Earmark - Elixir's Markdown Converter
Earmark is a pure-Elixir Markdown converter.
It is intended to be used as a library (just call Earmark.as_html), but can also be used as a command-line tool (run mix escript.build first).
Output generation is pluggable.
- Table Of Content
- Options
- Contributing
- Author
First Post!

stefanchrobot
Thanks! I was using Earmark.parse to convert MD to plaintext, but the Earmark.as_ast is a much more convenient and simpler API to do the same job.
Most Liked

kip
@RobertDober thanks for all your work on Earmark, its a critical part of the ecosystem and you’ve made it better through your efforts.

MarioFlach
I started experimenting with the AST. Pretty straight forward for what I want to do:
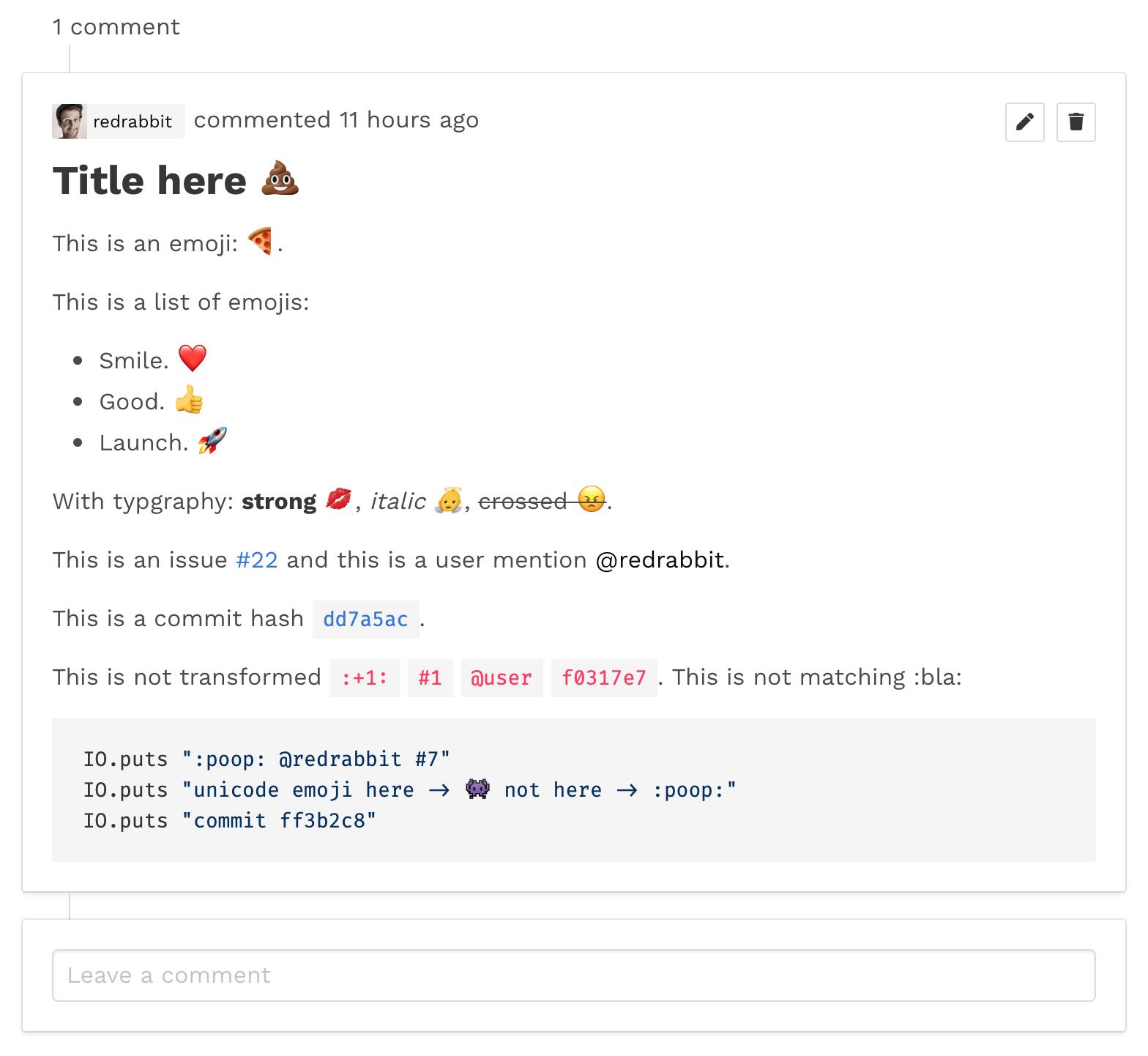
defmodule GitGud.Web.Markdown do
@moduledoc """
Conveniences for rendering Markdown.
"""
@doc """
Renders a Markdown formatted `content` to HTML.
"""
@spec markdown(binary | nil) :: binary | nil
def markdown(nil), do: nil
def markdown(content) do
case Earmark.as_ast(content) do
{:ok, ast, _warnings} ->
ast
|> transform_ast()
|> Floki.raw_html()
end
end
#
# Helpers
#
defp transform_ast(ast) do
ast
|> Enum.map(&transform_ast_node/1)
|> List.flatten()
end
defp transform_ast_node({tag, _attrs, _ast} = node) when tag in ["code"], do: node
defp transform_ast_node({tag, attrs, ast}) do
{tag, attrs, transform_ast(ast)}
end
defp transform_ast_node(content) when is_binary(content) do
content = Regex.replace(~r/:([a-z0-1\+]+):/, content, &emojify_short_name/2)
auto_link(content, Regex.scan(~r/#[0-9]+|@[a-zA-Z0-9_-]+|[a-f0-9]{7}/, content, return: :index))
end
defp emojify_short_name(match, short_name) do
if emoji = Exmoji.from_short_name(short_name),
do: Exmoji.EmojiChar.render(emoji),
else: match
end
defp auto_link(content, []), do: content
defp auto_link(content, indexes) do
{content, rest, _offset} =
Enum.reduce(List.flatten(indexes), {[], content, 0}, fn {idx, len}, {acc, rest, offset} ->
{head, rest} = String.split_at(rest, idx - offset)
{link, rest} =
case String.split_at(rest, len) do
{"#" <> number, rest} ->
{{"a", [], ["##{number}"]}, rest} # TODO
{"@" <> login, rest} ->
{{"a", [{"class", "has-text-black"}], ["@#{login}"]}, rest} # TODO
{hash, rest} ->
{{"a", [], [{"code", [{"class", "has-text-link"}], [hash]}]}, rest} # TODO
end
{acc ++ [head, link], rest, idx+len}
end)
List.flatten(content, [rest])
end
end
RobertDober
I just released Earmark 1.4.6
-
Exposes the now stable AST in the quadruple format.
-
There are many important bug fixes, all known crashes have been fixed, some issues like code blocks in lists and better HTML support did not make it.
Thanks to all of you for your great bug reporting after 1.4.5 which was a rough one.
Here go the Release Notes:
-
366-simplify-transform
Kudos to Eksperimental -
348-no-crashes-for-invalid-URIs
Kudos to José Valim -
347-dialyxir-errors
Fixed some of them, alas not all
Last Post!

sodapopcan
You should probably focus on looking for some ancient debris… or at least invest in an enchanting table. Just sayin’…
Popular in Announcing








Other popular topics





Latest on Elixir Forum
Sponsor Spotlight

Develop your skills with books, videos, and courses.
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #elixirconf-us
- #advent-of-code
- #distillery
- #processes
- #api
- #forms
- #metaprogramming
- #security
- #hex
Our Sponsors

Build Elixir applications with speed and confidence.

Supporting innovation across the BEAM ecosystem.

We build reliable cloud platforms for business-critical systems.

Catch errors, track performance, monitor hosts and more.

Error tracking, logs, uptime, and Just Enough APM. Built for developers.
Develop your skills with books, videos, and courses.

Enabling companies to succeed by building software people love.

The deployment platform built for Elixir: PaaS ease, VPS control.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.

Courses that'll move you from confusion to "Aha, now I get it!"