May I present exor_filter! You can find the library on my github. It is a nif wrapper for the xor_filter. A xor_filter is like a bloom filter, but is faster, has a smaller memory footprint, and has a smaller false-positive rate than bloom filters!
There are a good amount of use cases, but I was planning on using it for a bad-word filter for the commenting system on my personal blog. I think this one will cover l33t speak better than a bloom filter, because it is less memory constrained.
An issue that I believe exists is loading a large volume of values on initialization. If this is done other on startup, it could delay the VM due to it not being a dirty nif. However, it wouldn’t make sense to make it dirty due to the low access time of the filter. Its a bit of a catch 22. Using the xor8_buffered_initialize function could help, as the original repo says the buffered initialization is faster.
More information could be found in the linked original repository.
This is excellent. I think I’m going to use your code as a template for understanding erlang resources and to make sure I can have good support for them in my zigler library.
Awesome! This is my first nif so it may not be 100% correct, I have yet to profile the memory for leaks. I found the official documentation a bit confusing, so I worked off the jiffy library as an example on how to do it.
I have pushed an update to his library. It now includes 2 default hashing mechanisms, as well as an easier to use interface. Also, some issues with the C nif code have been resolved. Here is an example usage of the library (I’d add it to the first post but it seems that I can’t edit it anymore?)
Passing a list of any erlang term works now, instead of having to pass pre-hashed data. But the option to pass pre-hashed data or a special hashing function still is an option.
Next up is benchee to compare against ETS and a bloom filter nif!
Also, it seems that 10M records is quite slow to initialize, this might need to be split into two nifs. A dirty nif that does the loading if the list size is over 100K (?), then the second regular nif for just for access. The pass filter references would need to be passed between them…
Also, it seems there is no mechanism to send a fun to a nif and call it (besides coordination between a nif and genserver). Is this possible? It’d reduce the memory footprint for the custom hash functions as I could call the function as the filter is being assigned in the C code. A copy of the original list needs to be made at the current time…
Calling back into the VM is not efficient, message passing is expected to be used. Could have the custom function be Lua via luajit or support wasm or so?
I actually just pushed an update that chooses a dirty version of the nif if the passed list is over 10K records. So it was simpler than I thought Just exported two versions of the nif function.
Error when duplicate keys are present in the hash function and pre-hashed options, there is no longer spinning (hanging forever on initialization, which was a bit of an issue)!
A ‘raw’ interface to avoid this, use with caution. It is faster, because it doesn’t check for duplicates but doesn’t protect from the infinite initialization.
Convenience modules xor8 and xor16 .
Dialyzer fixes
Moar tests
Documentation updates.
Simplified C and erlang code.
Removal of fast_hash option, as duplication checking would have voided the usefulness.
With the convenience modules added, usage is now simplified:
perhaps someone can check me if I’m wrong, but your filter selector https://github.com/mpope9/exor_filter/blob/v0.3.0/src/exor_filter.erl#L296 is O(N) in list length, due to the length/1 call, which you may or may not want. I mean obviously you have to eventually traverse the entire list to unmarshal it, but you will be going over potentially super-long lists more than once.
in theory since it’s boxed anyways, there’s no real reason why erlang couldn’t have tagged their list indices . You might be able to record that length once outside and pass it in? But this might be premature optimization. I imagine the primary use case will be to prepopulate it once, when it’s okay to be slow (like on boot, or like daily updates)
I think its because the space cost. It would increase the size of each cons-cell by ~30%, but only as long as lists remain “short” (shorter than an unsigned pointer sized integer could represent), then all of a sudden we have big ints in the conscell, and those get expensive quickly…
As soon as this limit has been passed, you wouldn’t even be able anymore to cons in constant time, as increasing a big int is not O(1) anymore!
that’s a good point! But I don’t think you can realistically cons a list that is bigger than 2^64, since even at one byte per that’s probably about 10-100x more data than the NSA has in utah.
Actually just thought of a workaround, is_greater_than_10_thousand, which would return true at 10001 iterations. Will work that next. There is also an improvement to the underlying library which will increase initialization speed in some cases. Will bundle these together when I’m free.
A few new features have been added, included serialization of the filter to binary. This is useful for sending across networks or storing in databases. Also fixed a compiler error on Erlang 23. If below Erlang 23 is needed, version v.0.5.1 is recommended.
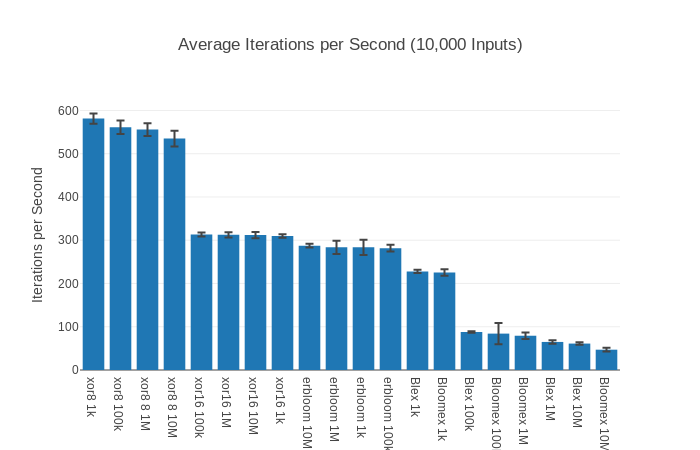
Also got around to benchmarking the library! Here is the benchmark suite. It compares results to several bloom filter libraries, one that is also a nif. The results look great, so if you’re using a bloom filter you should consider switching!
This version adds an incremental initialization api. The previous api required you to pass the entire list. Now, the list can be assembled in the nif over time, which should be more memory efficient. Here is an example:
Filter0 = xor8:new_empty(2), %% new_empty/0 defaults to 64 elements. Either function
%% will dynamically allocate more space as
%% needed while elements are added.
Filter1 = xor8:add(Filter0, [1, 2]),
Filter2 = xor8:add(Filter1, [3, 4]), %% More space allocated here.
Filter3 = xor8:finalize(Filter3), %% finalize/1 MUST be called to actually intialize the filter.
true = xor8:contain(Filter3, 1),
false = xor8:contain(Filter3, 6).
Deduplication of input data for the incremental initialization api isn’t supported yet, nor is a dirty nif api for large input initialization. finalize will fail if dups are present. The next release will add support for those.
Version v0.7.0 has just been released! This version adds deduplication of input to the incremental initialization API. This means there is a stable API to load data over time without having to do any tracking of data outside of the filter. Example:
 Just exported two versions of the nif function.
Just exported two versions of the nif function. . You might be able to record that length once outside and pass it in? But this might be premature optimization. I imagine the primary use case will be to prepopulate it once, when it’s okay to be slow (like on boot, or like daily updates)
. You might be able to record that length once outside and pass it in? But this might be premature optimization. I imagine the primary use case will be to prepopulate it once, when it’s okay to be slow (like on boot, or like daily updates)