pcapel
Giving a `nil` for `MyApp.Repo` configuration's `:pool` creates error
So, it seems like there is an issue where the value of the configuration for :pool in the Ecto configuration of a Phoenix application results in attempting to use nil as a module. You can minimally see this behavior by creating a new Phoenix application, setting the config :app_name, AppName.Repo, pool: nil and then attempting to create a simple migration.
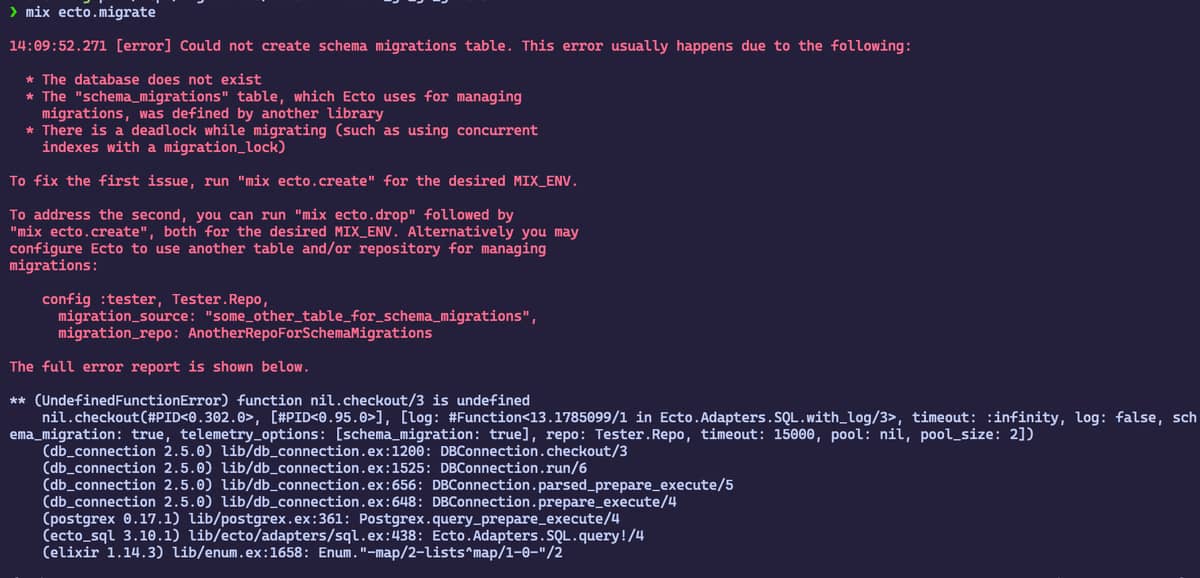
I’m wondering if this is expected behavior and I’m just not understanding how to configure things correctly?
The issue I have with this is that I’d really prefer to manage all my configuration using Dotenvy and a runtime config. But because sending nil is treated as sending a value and doesn’t result in a default value being used, that breaks.
I can work around this by checking the environment and configuring things differently, but that feels pretty off to me. Is this just a thing to work around, or should I consider other approaches?
Most Liked

Exadra37
For anyone to be able to help you you need to provide the relevant parts of your config files where Ecto is being configured.
Also, prefer to past everything as text inside a code block, instead of using images.
joey_the_snake
Map.get actually knows the difference as well it’s just that the default value is nil unless otherwise specified. But both functions detect whether a key is present or not and act according to their specification. None of them treat nil as a missing key. For example:
iex(3)> Map.get(%{a: nil}, :a, "test")
nil
iex(4)> Map.get(%{a: nil}, :b, "test")
"test"
Exadra37
I also prefer to only use runtime.exs as much as possible, except for when it’s not possible.
I have proof of concept for a unrelated thing, but in the the docs you can read how I use runtime.exs:
https://github.com/Exadra37/elixir-phoenix-360-web-apps/blob/dev_runtime-wip/TRY_IT_OUT.md
Popular in Questions








Other popular topics






 Latest Phoenix Threads
Latest Phoenix Threads
Latest on Elixir Forum
Sponsor Spotlight

Supporting innovation across the BEAM ecosystem.
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #advent-of-code
- #elixirconf-us
- #distillery
- #processes
- #forms
- #api
- #metaprogramming
- #security
- #performance
Our Sponsors

Build Elixir applications with speed and confidence.
Supporting innovation across the BEAM ecosystem.

We build reliable cloud platforms for business-critical systems.

Catch errors, track performance, monitor hosts and more.

Error tracking for Elixir devs who love to ship. Start your free account.

Practical resources that improve the lives of professional developers.

Develop your skills with books, videos, and courses.

The deployment platform built for Elixir: PaaS ease, VPS control.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.

Courses that'll move you from confusion to "Aha, now I get it!"