I mostly program in Python. as I’ve gotten more used to doing parallel stuff I’ve learned that python’s global interpreter lock causes threads to wait in line before executing.
My friend told me about Erlang and elixir and seemed to believe it was naturally more parallel.
My question is - what are the specifics (novice level) of how Erlang and elixir manage multiple threads? is it more powerful than python? how does it work?
I have a use case that I’ve had some difficulty getting to work in python because of the global interpreter lock so I wonder if Erlang would be a better fit. But I don’t want to run into the same “effectively single threaded” situations.
Novice level of a Python variety? Okay imagine the Stackless Python distribution without the GIL, that’s basically most of the BEAM. In slightly more detail it’s a lot of no-shared-memory little actors/microthreads/greenthreads that communicate via message passing thus meaning no GC contention thus meaning no GIL thus meaning it can scale as well as you can code, but very very safely.
Yes, true parallelism with BEAM. As @OvermindDL1 stated:
It is quite impressive. Because the BEAM is not using system level threads, you can spawn thousands, hundreds of thousands or even millions of processes!
Learn More About Elixir/Erlang
When I was first learning Elixir, I thought I was not going to have much of a problem, especially being a Lisper. I thought I had a core understanding about functional languages, and this new way of thinking about processes and such an amazing idea. However, Elixir’s Ruby-ish syntax confused the out of me! Because I was familiar with Ruby, I kept finding myself approaching everything in an object-oriented fashion and spaghetti-ing up this weird mash-up of things that did not make sense. Anyway, I think what I am getting at is that what finally what made me understand Elixir was learning the source of all of it; Erlang. I pulled away from Elixir, started at Learn You Some Erlang for Great Good!, then Erlang Docs. After playing with Erlang for a while, I came back to Elixir and I loved Elixir even more. Especially after learning about the Elixir Macro system. After seeing how correct the macro system is, I have started calling Elixir my New Lisp.
interesting, is there a tutorial that will walk me through making use of, and see the limits of this parallel power? I made a phoenix app once, but I’ve never really worked with pure elixir. It honestly seems like a new paradigm the way people talk about it, but the way I’ve seen it used so far works according to linear (do-one-thing-at-a-time) paradigms.
Yes, I get the feeling you actually understand more than you think you do, but are just unsure.
Forget Node.js. Forget Node.js. Forget Node.js. It’s concept of “concurrency” is a con job.
In Elixir/Erlang, you write sequential code as plain sequential code, without baroque workarounds to allow other code to run when one sequence blocks, and the runtime switches between code sequences appropriately. It is as though you were writing code to run in “normal” threads, except that suddenly they’re less expensive and you can have as many as you want. (Well, as long as you don’t want much more than 100,000,000 or so…) And you cannot have weird race conditions on access to shared data, because you cannot share data…
but you can share messages, so with consensus algorithms you can essentially share state. Has anyone built plugins for the language that implement consensus algorithms amongst the workers? is that too computationally intensive for workers? are they limited?
Yes, but now we are into a different territory than just concurrency and parallelism. This is generally for distributed computing and not something you would need just running one node.
I don’t think anyone uses these for just organizing erlang processes.
The unit of concurrency in erlang is the process. The processes gets scheduled over a number of scheduler threads. Usually 1 per core of your computer. Each process then gets a number of reductions to run before another processes gets a turn. This means a process cannot “hog” a scheduler for any period of time and every process gets its fair share of computing power. This gets you the stable low latency result you normally see in a BEAM language.
The scheduling is completely opaque to the programmer however. The only thing you need to do is write code and let it run in one or more processes. The computation in each process is serialized and the state in the process will not have the normal concurrency problems you normally see solved with mutexes, semaphores and other types of locks.
What is the use case? Erlang/elixir might be a good fit for it but it depends on if you can decompose your task to fit erlang’s processes.
It definitely is a different concurrency paradigm, but it is not ‘new’. It is known as the Actor Model. I emphasize concurrency paradigm, because it can be combined with different other programming paradigms. While functional programming combines with the Actor Model very nicely because of its focus of referential transparency and no-shared-state, other implementations like the OOP-Actor Model language Pony exist as well.
Saying that the actor model is about consensus alrogithms is a bit like saying that concurrency is about locks: Not true! Those are there to do the opposite: sequentialize (in the case of locks) or collabotrate (in the case of consensus) as part of the bigger system. But using these types of techniques should obviously be done sparsely rather than everywhere, because then you completely subvert the features of your system.
Also: ‘Concensus mechanisms’ (You seem to be speaking about distributed consensus here, looking at your links to Raft) are only interesting when we have multiple peers that might be separated by an untrusted and unreliable network! Inside the virtual machine of a single Elixir system (or even when setting up multiple Elixir nodes and connecting them using Distributed Erlang), using these kinds of mechanisms does not make any sense, since parties can immediately communicate, the network is trusted and transparent, and all peers can be trusted as well since they are all operated by you.
There are much easier ways to share state between processes: The easiest way is to send a copy of your own state to a different process. Also, Elixir processes allow you to perform not only asynchronious calls, but also, if you need to, perform synchronious calls, making sure that two processes are (for the duration of that sync call) both in a known state, which makes it a lot easier to reason about the system.
Elixir(Erlang) process is basically four blocks of memory: a stack, a heap, a message area, and the Process Control Block (the PCB). It is not a thread like a thread in C++. So Elixir process is just a memory. Erlang virtual machine(BEAM) run commands(instructions) of stack of process in real thread (thread like in C++) until 2000 functions of a process are called. (One function call is reduction) After this a process is queued and BEAM takes the next process(memory blocks) from the queue and run its stack commands on the real thread. Basically the BEAM has one real thread(like thread in C++) per CPU(Core) so it can run in parallel as many Elixir(Erlang) processes as there are cores. So at every moment of time the one Elixir(Erlang) process (the commands of the ‘process’) is running in the real thread. That is why you can have so many Elixir processes because process is just a memory. Erlang compile you program code into its own instructions so theoretically BEAM can run one instruction of a process per time and then switch to instruction of the next process. But in this case it will be difficult to analyze the state of the process in case of errors. For this reason, the BEAM counts the number of functions calls of process and then switch to next process. It works because in Elixir there are no loops like ‘for’ or ‘while’ and so on. Loops are implemented through recursive function calls. So it is hard to write coded without functions. And it is hard to hang in the body of the function.
I think this answers my original question pretty clearly. So if I have 8 cores and I instantiate 8 erlang processes (all doing the same arbitrary computation), those 8 erlang process will take as much time to run as if I just instantiated 1 erlang process, right? (because they run in parallel, one per core).
That’s what I would call ‘true parallelism.’ is my understanding correct?
Roughly. Assuming your hypothetical processes are independent, not passing messages amongst themselves, waiting for responses, accessing the same external resource, etc…
In general you what the number of processes in erlang/elixir to be much greater than the number of cores. So if you have 8 cores you want to have 10,000 processes or the like. As the scheduler will want to swap things in and out as processes block and so on
To be a bit picky here. The stack and the heap are actually in the same memory block, at each end of it growing towards each other. Messages can also end up in the memory block or in a separate memory area depending on how you decide to configure the process.
The threads running the erlang code in the BEAM are called schedulers. As mentioned by default you get one per core but you can also set the maximum number of schedulers at start up time and, what is really fun, change how many you actually use at run-time.
I normally don’t refer to my own presentations (honestly) but here is an overview of the BEAM which could be interesting for newcomers Hitchhiker’s Tour of the BEAM.
There has been an enormous amount of work done in the BEAM to ensure that it balances load properly and does not block. You really have to work to block it! It is quite a chock after working on the BEAM when you come to systems where you have to think about things blocking and making sure that it doesn’t.
Indeed, Akka, C++ with Boost ASIO, Lua coroutines–you have to be careful what functions you call, and the wrong choice leaves a latent latency bomb just waiting to be detonated under unusual load…
Yes, you are right. If you system has only 8 processes without side effect they will take as much time to run as if you just instantiated 1 Erlang process. This is true parallelism.
Moreover, If you PC has only one Core than 8 Erlang processes will be executed !concurrently! in one core. But in this case even if one of the processes calculates the factorial of 1000.000.000 this will not affect other processes. Because each process gets 2000 reductions to perform its tasks, after which the BEAM switches to the next process.
A cool thing about BEAM is that it creates one scheduler for each core. So, you do not have to mange any of that at all. It is quite seamless. As @MobileDev360 said, if all those processes have no side effects, there will be “true parallelism.”
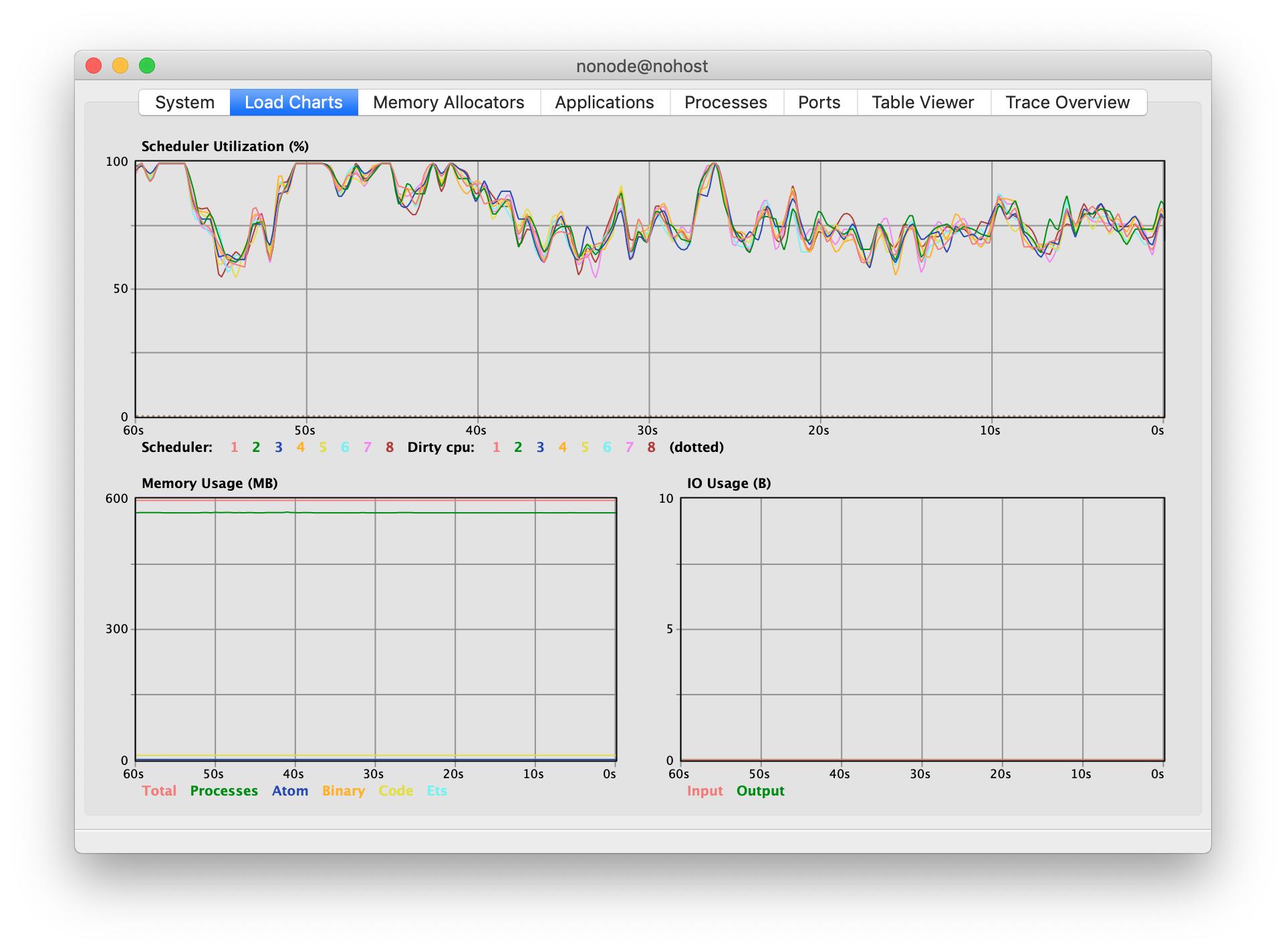
Check out the above, a program I created that is using thousands and thousands of processes to do a bunch of mathematical calculations – all spread across all 8 cores.
We do have true concurrency, doing independent things on possibly dependant data or shared resources.
Parallelism means doing the same operations at the exact same time on independant data. You can achieve this using SIMD (Single instructions, multiple data) capabilities of the CPU or using capabilities of your GPU.
The BEAM has no access to either of those.
But of course, the true concurrency we have is a million billion times better what we have about everywhere else.
I have never seen that claim before, not ever. Parallelism is generally, widely, I’d claim universally, accepted to mean operations happening at the exact same time, with no requirement that it be multiple instances of the same operation.
Well, thats how I learned it from university. But yes, in reality (even on that university) a less strict meaning was uses: “Doing independent operations on independent data and without any shared resources”.
CPU cycles, or time in general was not considered a shared resource by most of us in this definition, only during the real time lectures which I sadly was not able to participate in the practical course due to early failing some exams…