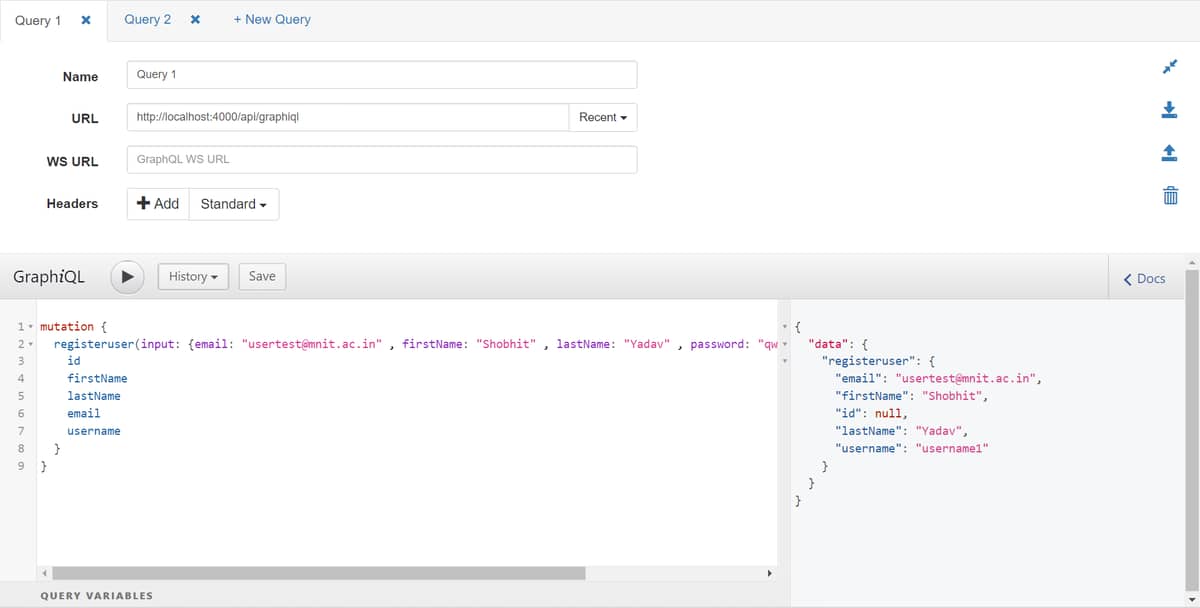
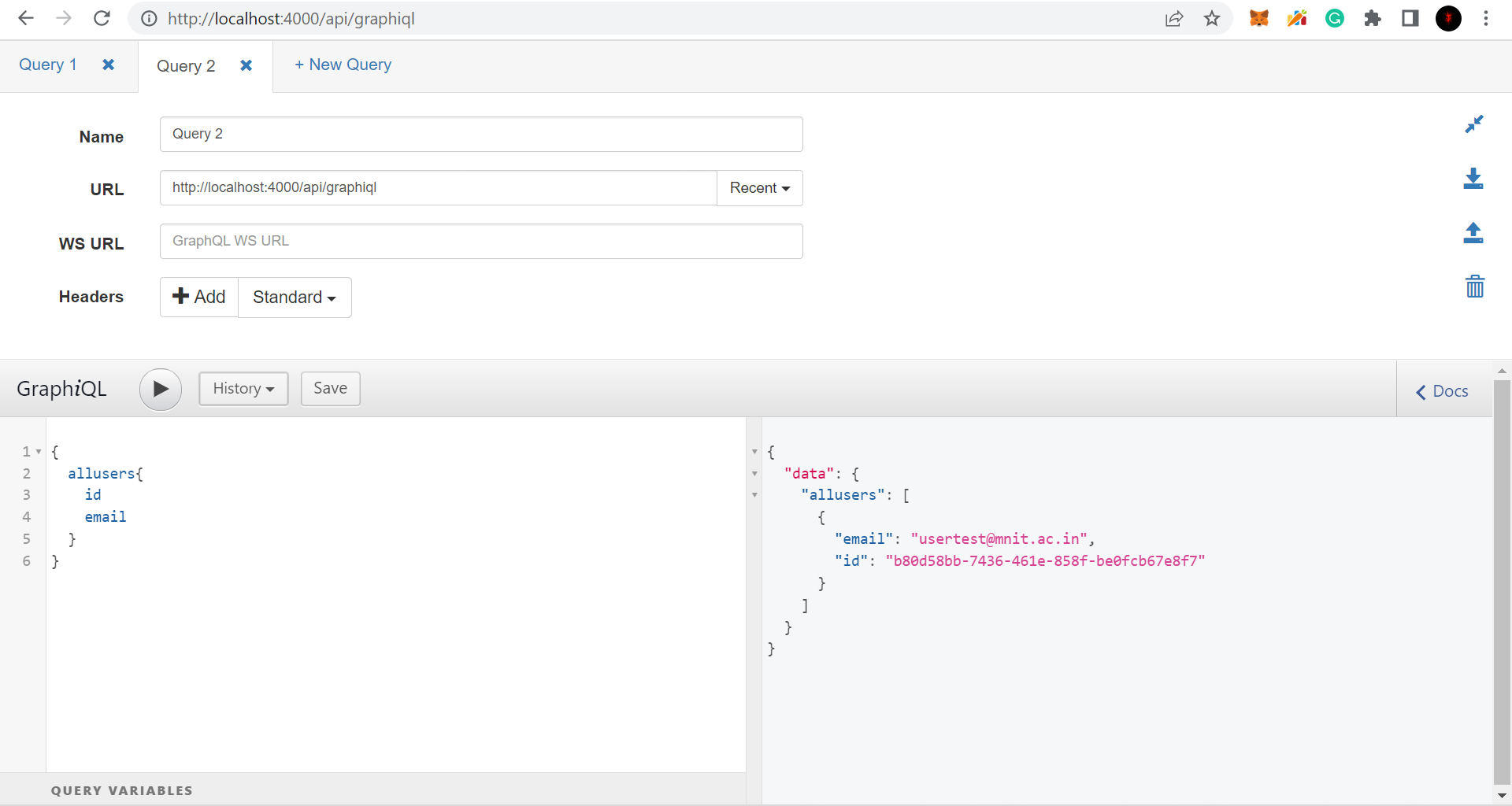
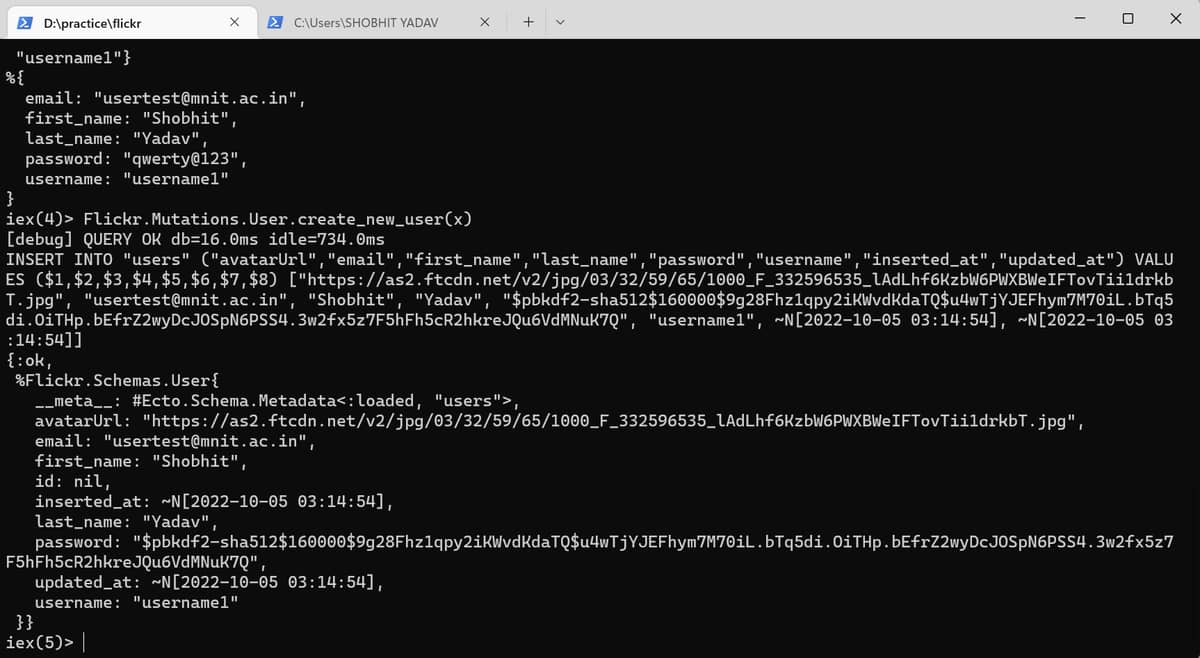
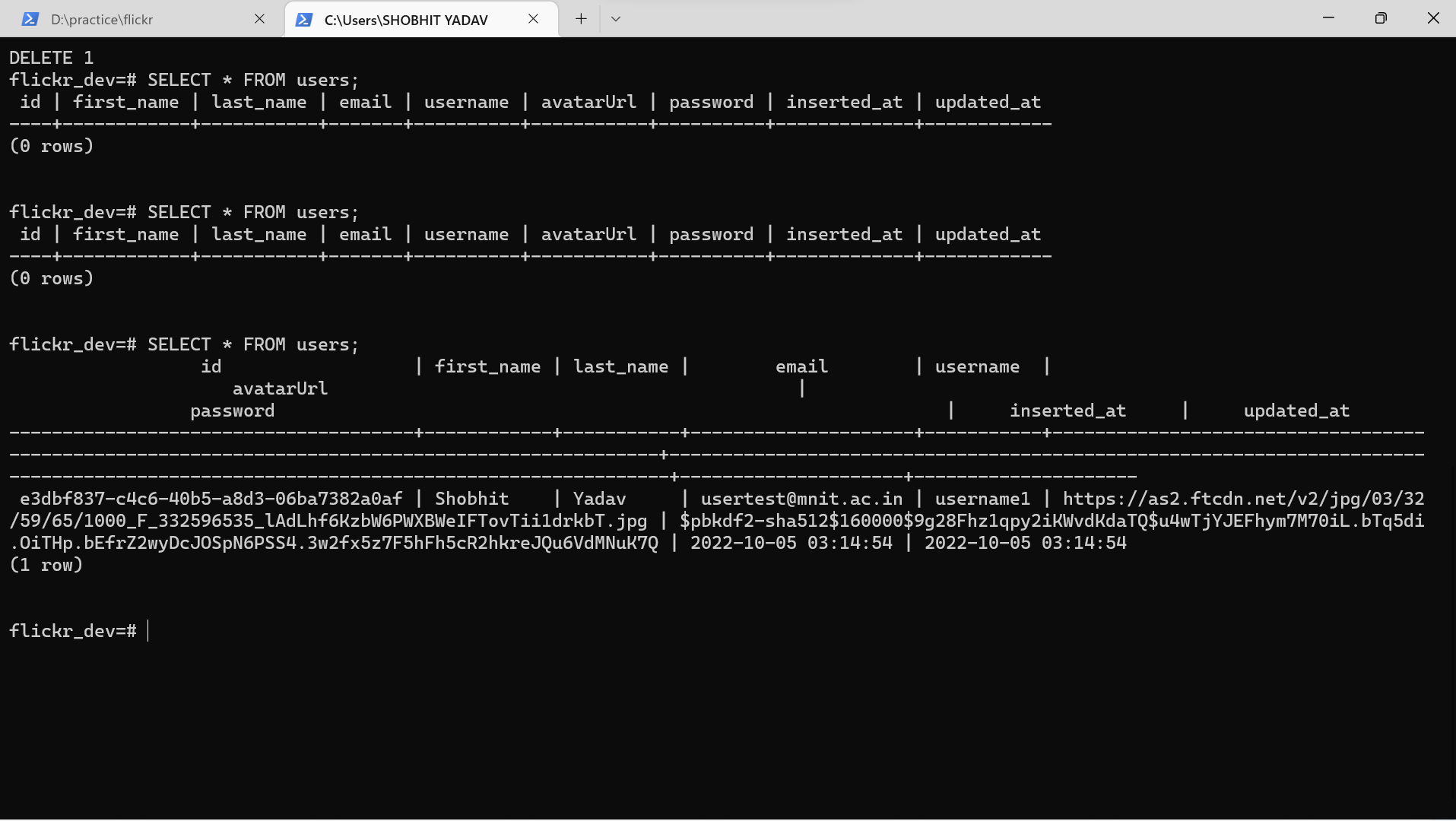
I was working with absinthe for my new side project but i am getting primary key as null when i register the user but when i return all the users with another query i am getting the id as well. I have no idea how to fix this.
This is my Absinthe Schema
defmodule FlickrWeb.Schema do
use Absinthe.Schema
alias FlickrWeb.Resolvers
#import Types
import_types(FlickrWeb.Schema.Types)
## Reddit Part
#Queries
query do
@desc "Just for testing"
field :test , :string do
"Test passed"
end
@desc "All users"
field :allusers, list_of(:user_type) do
resolve(&Resolvers.UserResolver.allUsers/3)
end
end
#Mutations
mutation do
@desc "Register a new User"
field :registeruser , :user_type do
arg(:input , non_null(:register_input_type))
resolve(&Resolvers.UserResolver.register_user/3)
end
end
end
These are my types:-
‘’’
defmodule FlickrWeb.Schema.Types.Usertype do
use Absinthe.Schema.Notation
object :user_type do
field :id, :id
field :first_name, :string
field :last_name, :string
field :email, :string
field :username, :string
end
input_object :user_input_type do
field :first_name , non_null(:string)
field :last_name , non_null(:string)
field :email , non_null(:string)
field :password , non_null(:string)
field :username, non_null(:string)
end
input_object :register_input_type do
field :first_name , non_null(:string)
field :last_name , non_null(:string)
field :email , non_null(:string)
field :password , non_null(:string)
field :username, non_null(:string)
end
end
‘’’
And this is my User Schema
‘’’
defmodule Flickr.Schemas.User do
use Ecto.Schema
import Ecto.Changeset
@type t :: %__MODULE__{
id: Ecto.UUID.t(),
first_name: String.t(),
last_name: String.t(),
password: String.t(),
email: String.t(),
username: String.t(),
avatarUrl: String.t()
}
@primary_key{:id , :binary_id , []}
schema "users" do
field :first_name, :string
field :last_name, :string
field :email, :string
field :username, :string
field :password, :string
field :avatarUrl, :string, default: "https://as2.ftcdn.net/v2/jpg/03/32/59/65/1000_F_332596535_lAdLhf6KzbW6PWXBWeIFTovTii1drkbT.jpg"
timestamps()
end
def insert_changeset(user , attrs) do
user
|> cast(attrs , [:first_name, :last_name , :email , :username , :password , :avatarUrl])
|> validate_required([:first_name, :last_name, :email , :username, :password, :avatarUrl])
|> update_change(:email, &String.downcase(&1))
|> unique_constraint(:email)
|> unique_constraint(:username)
|> validate_format(:email , ~r/@mnit.ac.in/)
|> validate_length(:username, min: 6 , max: 30)
|> validate_length(:password, min: 6 , max: 20)
|> hash_password
end
defp hash_password(changeset) do
case changeset do
%Ecto.Changeset{valid?: true, changes: %{password: password}} -> put_change(changeset, :password, Pbkdf2.hash_pwd_salt(password))
_ -> changeset
end
end
end
‘’’
This is my creating new user Function:-
‘’’
defmodule Flickr.Mutations.User do
import Ecto.Query, warn: false
alias Flickr.Repo
alias Flickr.Schemas.User
def create_new_user(attrs \\ %{}) do
%User{}
|> User.insert_changeset(attrs)
|> Repo.insert()
end
end
‘’’