I am creating my first umbrella application and I was wondering if there was a standard for breaking an app down and how it was accessed.
There are two ways I am considering building them and I am hoping that an answer to this question will help give me a much better understanding of umbrella projects.
In the umbrella project there will be the apps: user_ui (Phoenix), admin_ui (Phoenix), datasets (Elixir + Ecto).
The first example I have an umbrella with just those three applications. I would serve both the user_ui and admin_ui through Phoenix on different ports, then later us Nginx to serve to different URLs in production. Each app would make their own requests to the datasets application. This was my first instinct because coming from a Rails background I used to use Rails as an API and use a front-end framework like React or Ember for the front end and this felt somewhat similar.
After a little bit of thought though I couldn’t see the benefit of keeping it within an umbrella if I used that style and had well named Contexts. This lead me to the idea of adding an additional application called main that would be more like a “Context” for the whole umbrella app where it understands all the applications within the umbrella app and contain functions for utilizing them.
What are your opinions on the architecture of my future application and am I understanding the underlying concepts behind using Umbrellas.
I still struggle a bit with the umbrella stuff myself, so take this with a healthy dose of salt…
My understanding of umbrellas and when to use them is basically: when your project is super successful with millions of users, you will likely deploy certain applications to different servers, but you’re not there yet.
Let’s take a dashboard app as an example: when you’re processing TBs of data and serving millions of customers, it will likely make sense to have the data processing done one (cluster of) server(s), while the “interaction” part serving millions of users is deployed to another (cluster of) server(s). But right now, when you’ve just got 5 friends using your app and are struggling to convince new users to join, it makes sense to just have everything on a single machine (for reasons such as costs, operational simplicity, etc.).
That’s where an umbrella app comes in: start with an umbrella so you can deploy (and test, etc.) the whole “monolith” at once easily, but when the time comes, splitting out the sub-apps for separate deployment will be easy.
I don’t believe you should use umbrellas for organizing code. That’s what modules (and contexts) are for.
Soft dependency boundary between the bigger parts of your entire thing. If you have these apps and they are dependent like so:
web -> business_logic -> storage
…then obviously web (your Phoenix website) should not directly call any functions from storage. It should go only to the business_logic functions for its data needs.
As others have pointed out in other threads, this is not a hard rule. Technically you could still skip the mediator if you are hellbent on it. But you have to work a little to achieve it which, my hope is, will send the message of “you know, you really should not be doing that”.
Deployment granularity. Mine might be an unpopular opinion but I go for umbrellas from day one. If any of your apps grow beyond your starting deployment needs, you can always just make only very slight changes in your Distillery configuration and just deploy the overgrown app somewhere else. Imagine that after a bit of metric collection you notice that 85% of the users waiting time is spent waiting on the DB instead of the Elixir code. You either (a) upgrade your database – which is usually the most expensive part of the hosting so not many want to do that – or (b) move your storage app to a bigger VPS (or managed) instance and utilize heavy caching (which might require more RAM than your previous instance had).
In short, I don’t find the umbrella apps as painful as some make them out to be. Sure you have to do a few things manually when invoking 3rd party generators because some of them are partially or not at all aware of umbrellas… but so far I haven’t found any problem I couldn’t overcome.
And lastly, even if your app(s) never grow so much as to justify pt. 2, having the semantic boundaries and separation of concerns that pt. 1 partially gives you is still worth it in my eyes.
Just to be clear I am not choosing an umbrella because I want to organize my code. I want to know a clear organized way to structure my umbrella app, and that I am creating several separate micro-services into separate applications to hopefully make the development of this project easier.
I was wondering the difference between running each services as isolated apps within the umbrella having each app have its own Contexts that have the implementation functions within versus creating an additional app that’s main purpose is serving all the micro-service applications. The app would understand hold every public facing function that the umbrella has so that users are not required to look through documentation for modules outside of one app within the umbrella.
Umbrellas are pretty good for organizing several projects in a mono-repo. I have also worked with several projects that depend on each other through paths and each has their own repo and it quickly becomes very tedious – one feature often requires 2+ pull requests (one for each affected repo).
You don’t have to have separate Contexts for each app. Not at all. In all my apps so far I have one of the apps inside the umbrella to be the business logic container. Whoever needs to work with the entities in the project is using its functions. You can specify dependencies inside an umbrella (add this to the deps section of your mix.exs: {:your_singular_app, in_umbrella: true} and that’s it).
As for all possible frontends, it’s up to you. I’ve mixed human UI with API endpoints in a single Phoenix project but from then on started isolating every frontend using a consistent naming scheme for each app inside the umbrella: myapp_web for Phoenix, myapp_graphql for Absinthe-enabled backends, and even myapp_rest when I needed REST. The sky is the limit.
The way I’m doing it for my current project is to split it up so that the main business logic is in individual apps, then the web frontend just calls services in the individual business apps. This way each has its own DB and can be split off as and when the time comes.
For other external apps, I have a graphql API that again calls into the business application services. That way other systems can just use the graphql API and they don’t have to know anything specific about the apps that live behind it.
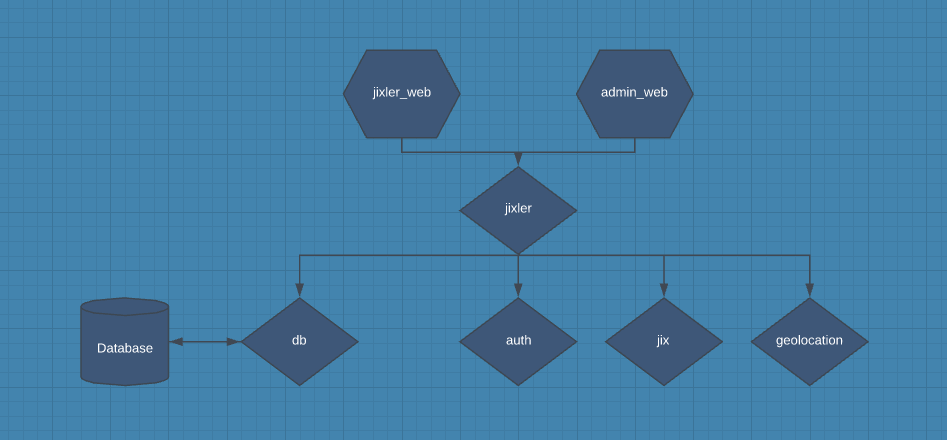
This is how I am thinking about setting up my umbrella. Within my db app I am going to have a db_schemas folder that is going to hold every schema. I have read that sometimes just the shared schemas are placed within the db app and specific schemas are stored within the apps, but this doesn’t make much sense to me if I can just store every schema in one location.
If I were to roll my own user authentication knowing that there is a :users table that is going to store both my users and my admins (through different schemas) I plan on keeping both schemas on the Db application. Would it be appropriate to create a Jixler.Accounts context on the jixler app and that is what is responsible for creating users and providing the changesets from the Db.Schema.User.
Please let me know what you think of a structure like this.