
vegabook
Adbc high memory usage compared with native drivers
adbc seems to use a huge amount more memory than “native” drivers.
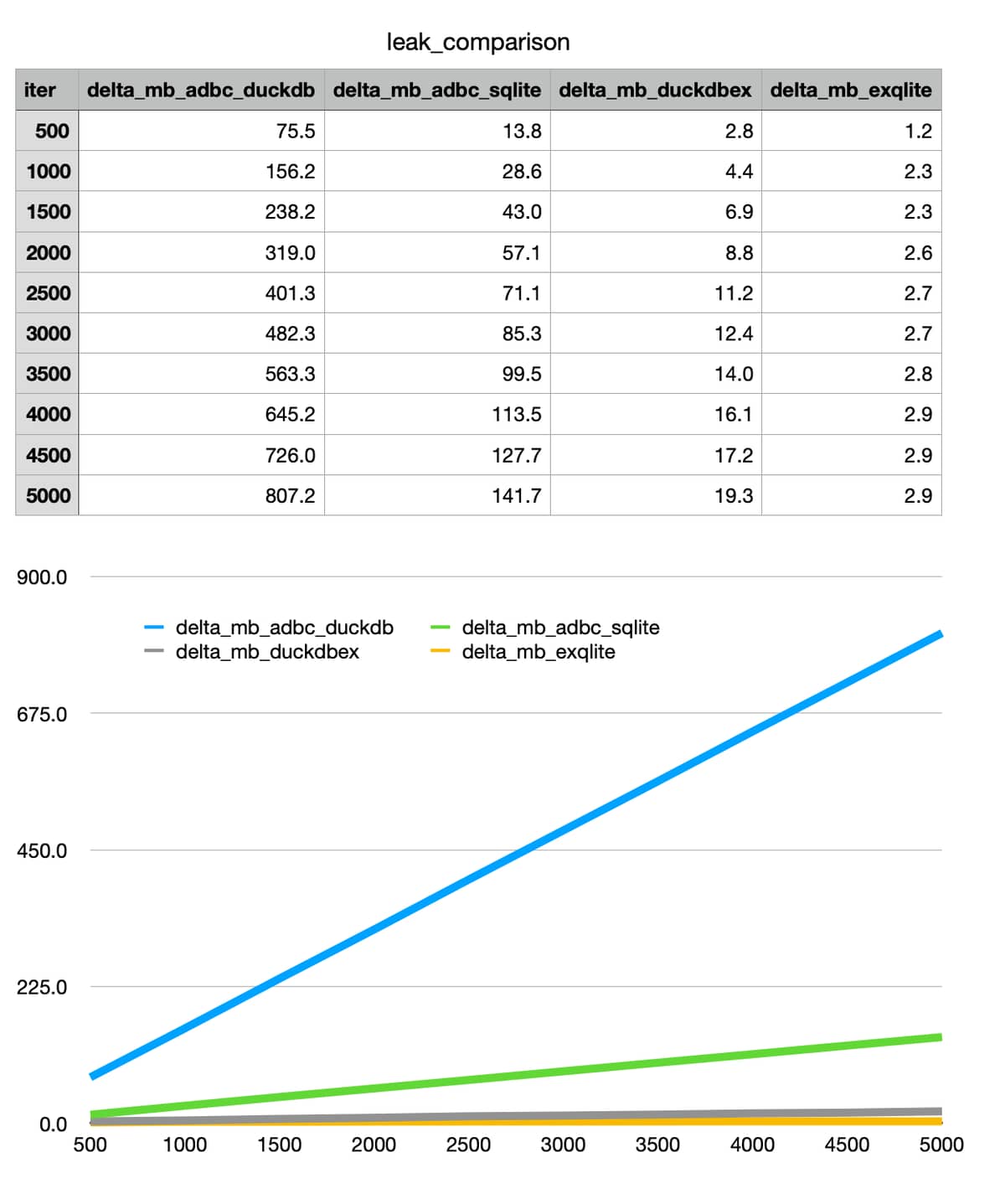
I’m dumping large amounts of data each minute, about 600k data points across 10k different identifiers. I need column store for querying so I have gone to duckdb via adbc. But it’s using tons of memory even though I am specifiying an on disk file. I have written a small test to show what I mean in this repo: GitHub - vegabook/adbc_leak_demo · GitHub . You’ll see that adbc basically accumulates memory, especially for duckdb, but also for sqlite, at a much higher pace than native drivers.
I’d like to stick to “offical” adbc if possible as it will also allow me more easily to swap out backends. So is this a bug or some implementation issue? What can I do to avoid this behaviour? As it stands it basically makes adbc difficult to use right now for append workflows as memory just keeps on growing forever. Even using sqlite backend the memory growth is kind of a concern. duckdbex is kind of acceptable as memory growth seems slow enough that a once-every-few-hours restart or something should keep thins manageable. But really only exqlite currently is fit for a long-running ingest, but it has the major downside of not doing column store so data science queries will be ultra slow.
Any advice on how to solve the “lots of fast ingest, must be column store, mustn’t leak memory” problem?
The table and chart show process memory growth as rows get ingested. Each iter is 100 rows. All are on-disk workflows so apart from a bit of buffer delta early on, you’d expect stability.
Popular in Questions







Other popular topics






Latest on Elixir Forum
Sponsor Spotlight

Courses that'll move you from confusion to "Aha, now I get it!"
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #elixirconf-us
- #advent-of-code
- #distillery
- #processes
- #forms
- #api
- #metaprogramming
- #security
- #hex
Our Sponsors

Build Elixir applications with speed and confidence.

Supporting innovation across the BEAM ecosystem.

We build reliable cloud platforms for business-critical systems.

Catch errors, track performance, monitor hosts and more.

Error tracking for Elixir devs who love to ship. Start your free account.

Producing high quality Elixir screencasts since 2017.

Enabling companies to succeed by building software people love.

The deployment platform built for Elixir: PaaS ease, VPS control.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.
Courses that'll move you from confusion to "Aha, now I get it!"