
webofbits
Squidie - workflow automation runtime for Elixir applications

Squid Mesh is an open source workflow automation runtime for Elixir applications.
It is aimed at Phoenix and OTP apps that want to define and run durable workflows in code without rebuilding the runtime layer around retries, replay, inspection, cancellation, and scheduling.
Core Idea
- define workflows declaratively with triggers, payload contracts, steps, transitions, and retries
- run them durably on top of an existing Repo and Oban
- inspect run history with step and attempt details
- replay and cancel runs through a small public API
- activate recurring workflows through cron-backed triggers
Current Features
- manual triggers
- cron triggers
- step retries with exponential backoff
- built-in
:waitand:logsteps - run inspection with history
- replay and cancellation
- HTTP tool adapter support
Example Workflow
defmodule Content.Workflows.PostDailyDigest do
use SquidMesh.Workflow
workflow do
trigger :daily_digest do
cron("0 9 * * 1-5", timezone: "Etc/UTC")
payload do
field(:feed_url, :string, default: "https://example.com/feed.xml")
field(:discord_webhook_url, :string)
field(:posted_on, :string, default: {:today, :iso8601})
end
end
step(:fetch_feed, Content.Steps.FetchFeed)
step(:build_digest, Content.Steps.BuildDigest)
step(:post_to_discord, Content.Steps.PostToDiscord,
retry: [
max_attempts: 5,
backoff: [type: :exponential, min: 1_000, max: 30_000]
]
)
transition(:fetch_feed, on: :ok, to: :build_digest)
transition(:build_digest, on: :ok, to: :post_to_discord)
transition(:post_to_discord, on: :ok, to: :complete)
end
end
Running from Host App
SquidMesh.start_run(Content.Workflows.PostDailyDigest, %{
discord_webhook_url: System.fetch_env!("DISCORD_WEBHOOK_URL")
})
Under the Hood
-
Oban for durable execution and scheduling
-
Jido for custom step actions
-
Postgres for persisted run state
Status
This is still an early alpha release.
Current focus:
-
API shape
-
workflow contract
-
runtime model
Links
-
Hex: squid_mesh | Hex
-
GitHub:
First Post!
webofbits
A bit more context on why Squid Mesh uses both Oban and Jido.
Oban is the durable execution backbone. Squid Mesh owns workflow state, retries, replay, cancellation, inspection, and step progression, but it still needs a strong execution layer underneath for queueing, scheduling, redelivery, and background execution across restarts and deploys. I didn’t want Squid Mesh to re-implement a job runtime when Oban is already very good at that layer.
Jido is currently used mostly at the step/action boundary. Right now that means custom workflow steps can be expressed as Jido actions instead of every app inventing its own step contract. That part is useful already, but I also think Jido could play a bigger role over time if Squid Mesh grows more agent-oriented execution patterns, richer action libraries, or more AI-heavy workflow steps. So today Oban is the more foundational dependency, while Jido is more about the execution contract and future direction.
On “why not just use Oban workflows?”: I think that’s a fair question. If a team already has Oban Pro and is happy building directly at that layer, Squid Mesh may be unnecessary. The reason this project exists is to provide a higher-level workflow runtime for application code: workflows as a first-class app concept, with a DSL, run/step/attempt history, replay, cancellation, cron-backed triggers, and a small public API around them. So the goal isn’t to compete with Oban as a job system, but to sit one layer above it.
If helpful, a simple way to describe the split is:
- Oban handles durable execution
- Jido handles custom step actions
- Squid Mesh handles workflow semantics
Most Liked
webofbits
i started laying the foundations and milestones for https://github.com/dark-trench/squid_studio (the visual editor)
it should help identify the remaining gaps in squidie to support visual editors
also, new name → new logo ![]()


webofbits
Longer term, this is something I could imagine building after the runtime matures further: a visual companion for inspecting Squid Mesh workflows and run state. For now I’m staying focused on the runtime, durability, and host-app integration, but I like the idea of eventually making workflow shape, transitions, retries, and manual gates easier to see at a glance.

webofbits



Last Post!
webofbits
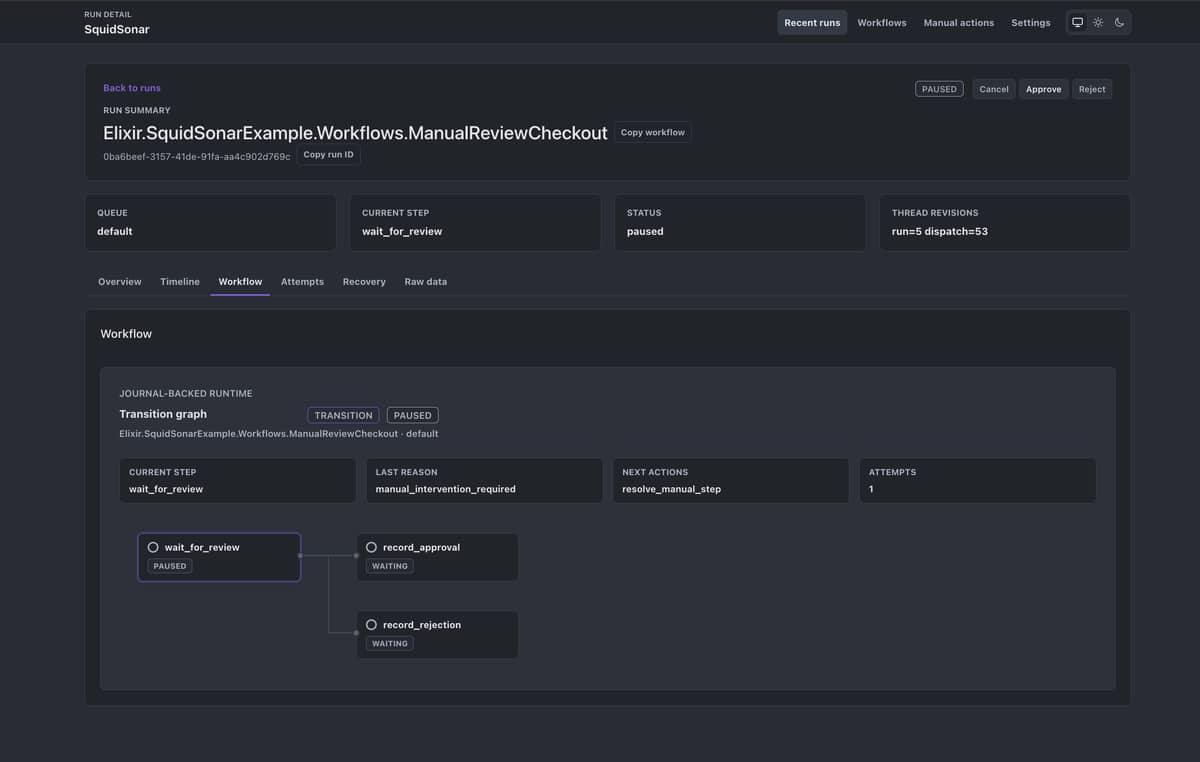
SquidSonar update
We’ve merged several improvements:
- Upgraded Phoenix and LiveView across the package and example app.
- Added tabbed run details with deep-linkable views for timelines, workflows, attempts, recovery, and raw data.
- Added chronological execution timelines with safe redaction and partial-data handling.



Popular in Announcing






Other popular topics




Latest on Elixir Forum
Sponsor Spotlight

Build Elixir applications with speed and confidence.
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #elixirconf-us
- #advent-of-code
- #distillery
- #processes
- #api
- #forms
- #metaprogramming
- #security
- #hex
Our Sponsors
Build Elixir applications with speed and confidence.

Supporting innovation across the BEAM ecosystem.

We build reliable cloud platforms for business-critical systems.

Catch errors, track performance, monitor hosts and more.

Error tracking, logs, uptime, and Just Enough APM. Built for developers.

Practical resources that improve the lives of professional developers.

Enabling companies to succeed by building software people love.

The deployment platform built for Elixir: PaaS ease, VPS control.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.

Courses that'll move you from confusion to "Aha, now I get it!"