
myronmarston
Comparing two GenStage Designs
After hearing @josevalim’s keynote at ElixirConf, I got inspired to re-write our application’s data-processing pipeline (which works OK but is pretty inefficient) to use GenStage. I initially imagined I’d build it doing something like this:
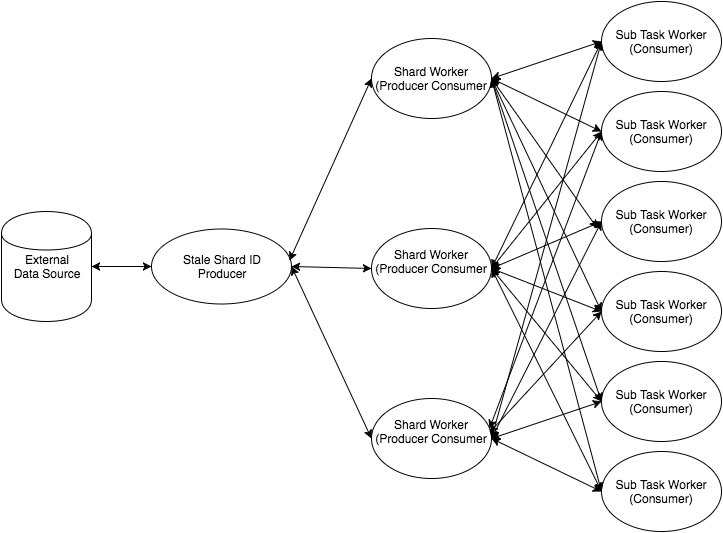
Here are the parts:
- The
StaleShardIDProducerperiodically reads from an external datasource to see what shards are stale due to newly available data snapshots, and produces stale shard IDs. - The
ShardWorkerstages are producer-consumers that receive stale shard IDs from theStaleShardIDProducerand produce a list of sub-tasks that must be performed to finish building the shard. - The
SubTaskWorkerstages perform the sub-tasks, and send the results back to theShardWorkerto be injested into the shard. When all sub-tasks have completed, the built shard is persisted.
I got started prototyping this and quickly realized that there’s a problem: when a producer-consumer (such as my ShardWorker) emits events from handle_events/3–as I was planning on having it do–that is treated as “finishing” the events it was given, and it will turn around and send more demand upstream even though it hasn’t finished building the shard (it needs to wait for all subtasks to complete for that). That would have the effect of having it “move on” to the next shard when we really want to make it wait until the shard is complete before requesting a new one from the StaleShardIDProducer.
From my understanding of GenStage at the time, I couldn’t figure out how to make this design work, so I tweaked it slightly:
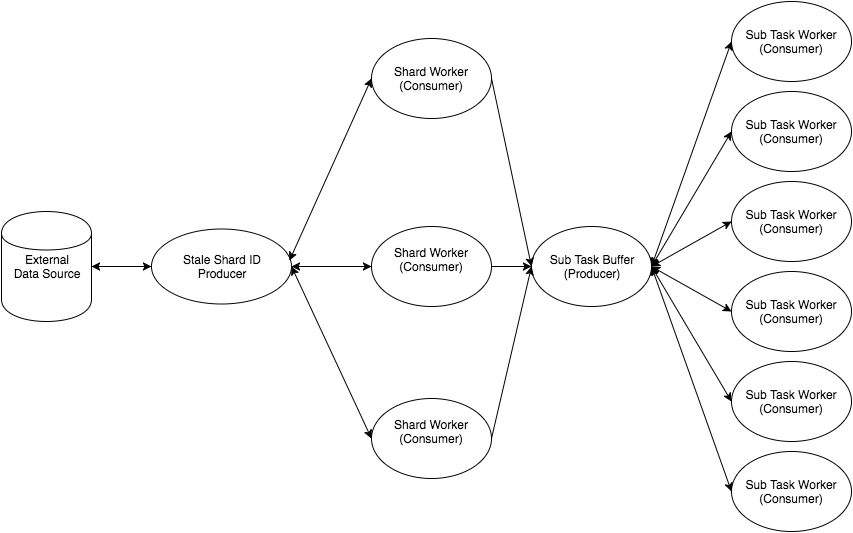
This design has a couple differences:
- The
ShardWorkerstages are consumers, which allows them to wait to finish an event until all the sub tasks are complete and it can persist the shard. - There are actually two GenStage flows here instead of just one. The
SubTaskBufferis a new producer that theSubTaskWorkerstages subscribe to. TheShardWorkerstages send sub-tasks directly to the buffer so they will get worked on. Essentially, theSubTaskBufferandSubTaskWorkerstages form a worker pool with the buffer as the entry point for clients to send work to.
I prototyped this, got it working, and was pretty happy with it. I haven’t gotten to implement a production version of this, though. And today I was re-reading the GenStage docs and noticed something I hadn’t noticed before: the optional handle_subscribe/4 callback allows you to implement a :manual mode, where demand is not automatically sent upstream. Instead, you send demand upstream when appropriate by manually calling GenStage.ask/3. If I’m understanding this correctly, I think this means that my initial design is possible – I just have to make the ShardWorker stages implement :manual mode, where they only demand a new stale shard ID after finishing and persisting a shard.
So now I’m wondering which direction to go. What are the tradeoffs between these designs? I easily understand how the worker pool works (in fact, I’ve built a productionized version of it) but I’m a lot fuzzier on how things work when you have N consumers subscribed to M producers. I’m hoping @josevalim can weigh in with a recommendation :).
Most Liked

josevalim
@myronmarston first let me clarify that, although the producer_consumer sends demand as soon as handle_events is done, those events are not consumed until demand is received from downstream. This is a form of pre-fetching to ensure we always have data in flux.
That said, the issue with your second design is that you no longer have back-pressure all the way. It won’t be a problem if the ShardWorker is the slowest layer in your pipeline but it also means you are not gaining anything by having two layers of GenStage.
For example, instead of a second pipeline, you could directly start the shard worker children directly in a supervisor:
/[consumer]\
[producer]-[consumer]-[supervisor]
\[consumer]/
It would work similarly to what you have designed: the shard worker will start multiple children in the supervisor and wait for those children to reply back.
However, my preferred solution would be to simply not do any asynchronous work in the stages. The question is: does the stale shard id producer provides enough events to make all shard workers busy, using 100% of your machine resources without the need to start subworkers?
Imagine the stale shard id producer can provide events faster than they can be consumed. In this case, you have enough work on each shard worker to use all cores without needing to break each shard worker in a subtask worker. In this scenario, if you have 4 cores and 4 shard workers, that will be enough. Breaking it into smaller tasks won’t buy you anything because all of the tasks will still be working towards the same 4 shard workers.
However, this may not be the case. You may process events faster than the producer can emit them. Or maybe the subtask workers are IO bound. In this case, you can also keep with a single stale shard id and multiple subworkers except you start multiple tasks (Task.async or Task.Supervisor.async) and await for them inside handle_events/3 for each subworker. This way you keep the synchronicity and still can break the work apart.
myronmarston
I would say that GenStage, as a library, only provides a unidirectional flow, but ultimately, each stage is a process, and can of course do normal Elixir/Erlang stuff like send messages. While it’s perhaps a bit non-standard to send results back, there are certainly valid reasons for doing so. (As I’ll explain below).
While I can see why you would think this, the ShardWorker stage does in fact wait on the sub task workers. In my prototype, it did so by calling this, as I showed in my answer to @josevalim above:
ShardProcess.perform_build(stale_shard_id)
ShardProcess here is a gen server, so this did the following:
- Started the gen server
- Waited for the gen server to completely finish building the shard and exit
The ShardProcess was responsible for sending sub tasks into the worker pool, keeping track of pending tasks, and receiving results until it got all results back–at which point it would persist the shard and exit.
Such a design would probably work, and might be conceptually simpler, but I don’t think it’s the one we will go with. The shard data structure we are building can get quite large (in the worst cases, multiple GB) and as such, we really only want it to exist in one process. Including it in a message to another process would involve copying the entire data structure, which would be quite slow.
In addition, we have designed the shard so that individual pieces (such as individual values in a map within the shard data structure) can be compressed individually. We get a pretty good compression ratio (about 20:1) so by having each sub task send its results back to the ShardProcess, it allows the ShardProcess to compress the results, and put it in the shard as sub tasks complete, which works out nicely to keep things from using more memory than needed. I don’t think we could get the same kind of benefits out of the design you have proposed.
Last Post!

ibgib
Thanks for taking the time to explain your feedback to me! ![]()
I’m using your use case as something to test GenStage and your additional info should be very helpful. Thanks again!
Popular in Questions







Other popular topics





Latest on Elixir Forum
Sponsor Spotlight

Producing high quality Elixir screencasts since 2017.
Categories:
Sub Categories:
Forums
Popular Tags
- #ecto
- #liveview
- #troubleshooting
- #learning-elixir
- #deployment
- #library
- #erlang
- #testing
- #genserver
- #mix
- #absinthe
- #remote-other
- #otp
- #plug
- #how-to-question
- #macros
- #postgres
- #channels
- #elixirconf
- #exunit
- #discussion
- #code-sync
- #javascript
- #podcasts
- #onsite
- #dialyzer
- #docker
- #authentication
- #umbrella
- #full-time-contract
- #podcasts-by-brainlid
- #ecto-query
- #elixir-ls
- #phoenix_html
- #iex
- #blog-post
- #graphql
- #genstage
- #ai
- #websockets
- #supervisor
- #elixirconf-us
- #advent-of-code
- #distillery
- #processes
- #api
- #forms
- #metaprogramming
- #security
- #hex
Our Sponsors

Build Elixir applications with speed and confidence.

Supporting innovation across the BEAM ecosystem.

We build reliable cloud platforms for business-critical systems.

Catch errors, track performance, monitor hosts and more.

Error tracking, logs, uptime, and Just Enough APM. Built for developers.

Develop your skills with books, videos, and courses.

Enabling companies to succeed by building software people love.

The deployment platform built for Elixir: PaaS ease, VPS control.

The team behind Membrane, Popcorn, LiveDebugger. Available for hire.

Courses that'll move you from confusion to "Aha, now I get it!"